
Introduction
Amazon.com is a vast Internet-based enterprise that sells all kinds of goods either directly or as the middleman between other retailers and Amazon.com’s millions of customers.
In this article, you will read about the easiest way to scrape Amazon products and reviews with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Amazon products into Google Sheets.
Amazon scraping can be very useful if you want to accomplish such tasks as:
- competitor analysis
- improving your products and value proposition
- identifying market trends and what influences them
- price monitoring
Luckily, Amazon.com is a website that is pretty easy to scrape if you have the right tools.
For this purpose, we will use Page2API - a powerful and delightful API that makes web scraping easy and fun.
In this article, we will learn how to:
- Scrape Amazon products
- Scrape Amazon reviews
Prerequisites
To perform this simple task, you will need the following things:
-
A Page2API account
The free trial offers a credit that covers up to 1000 web pages to scrape, and it takes under 10 seconds to create the account if you sign up with Google. -
A product or a category of products that we are about to scrape.
In our case, we will search for 'luminox watches'
and then scrape the reviews for a random product.
How to scrape Amazon products
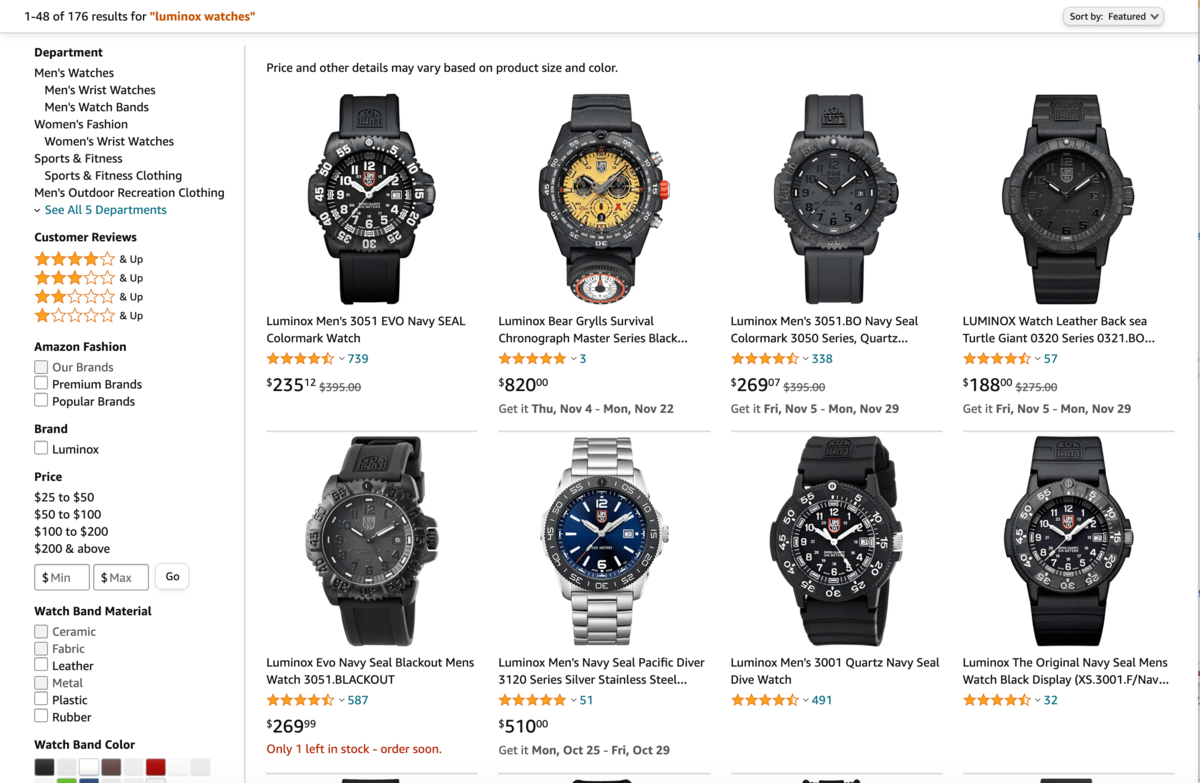
First what we need is to type 'luminox watches' into the search input from amazon's search page.
https://www.amazon.com/s?k=luminox+watches
The URL is the first parameter we need to perform the scraping.
The page that you see must look like the following one:
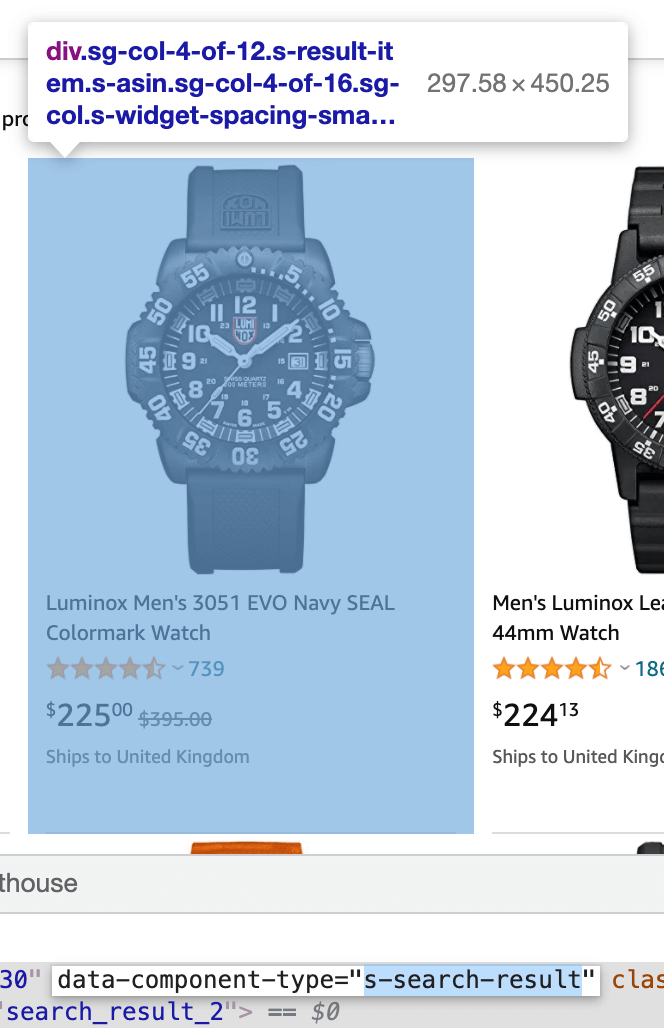
If you inspect the page HTML, you will find out that a single result is wrapped into a div that looks like the following:
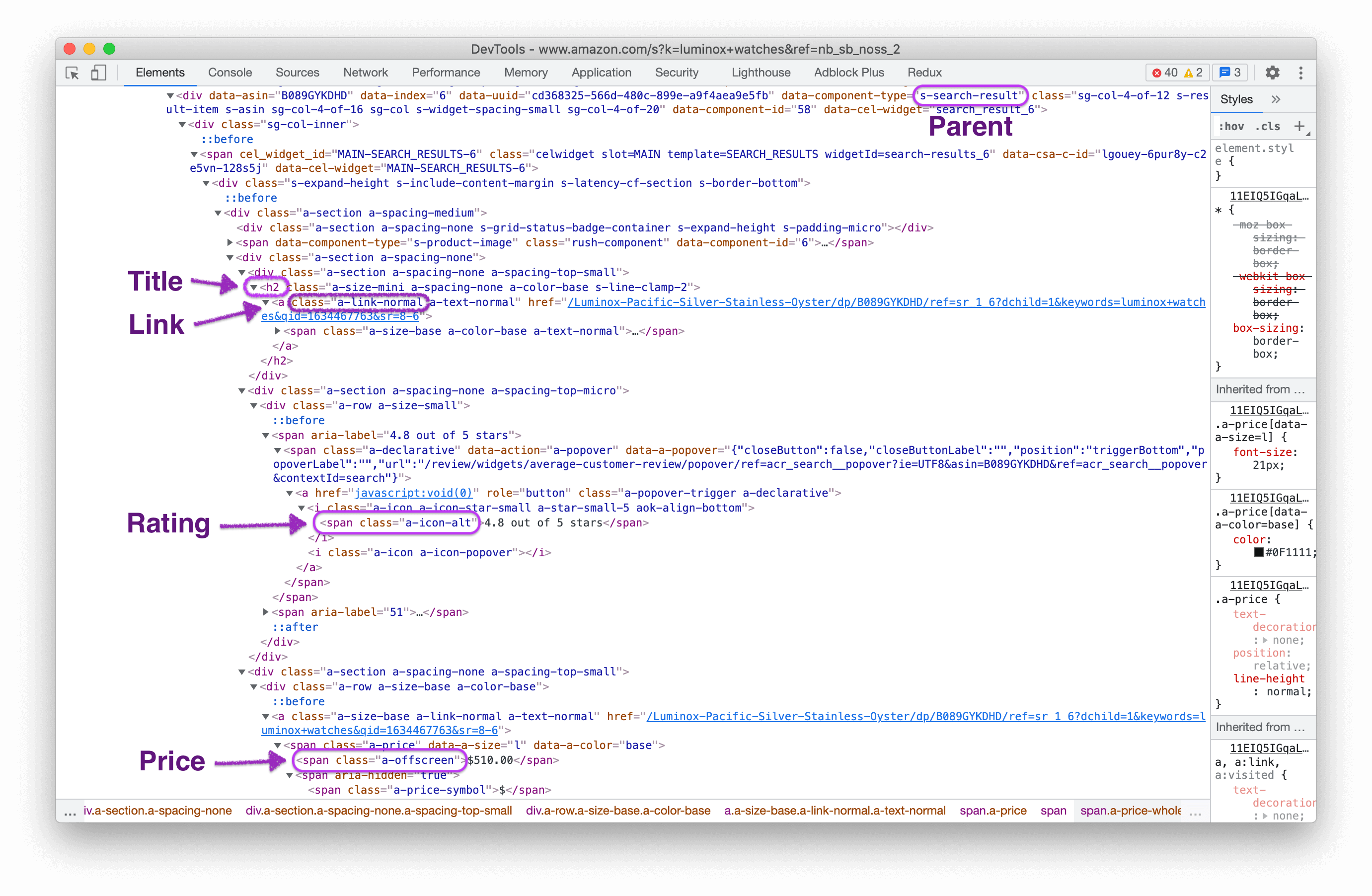
The HTML for a single result element will look like this:
Now, let's handle the pagination.
There are two approaches that can help us scrape all the needed pages:
1. We can iterate through the pages by clicking on the Next page button
2. We can scrape the pages using the batch scraping feature
Let's take a look at the first approach.
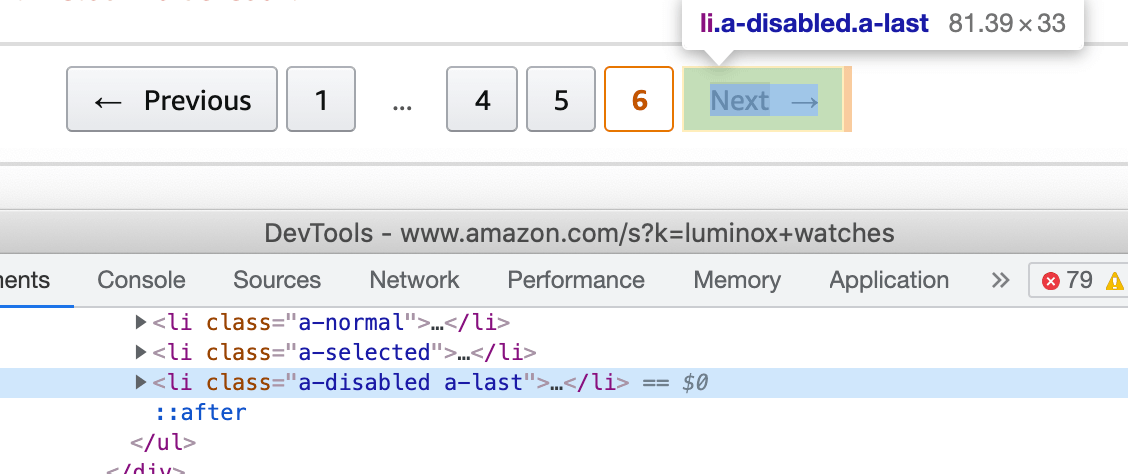
In our case, we must click on the Next → button while the list item's class will be active:
document.querySelector('.s-pagination-next').click()
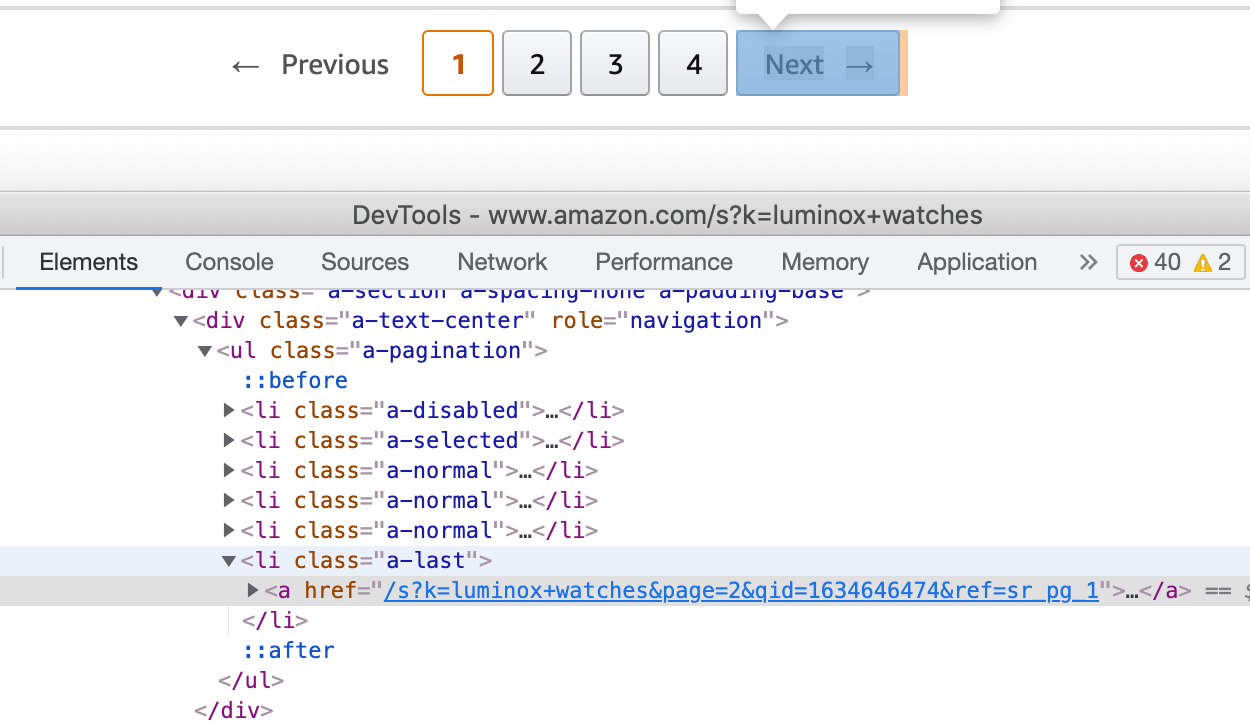
And stop our scraping request when the Next → button became disabled.
In our case, a new class (.s-pagination-item.s-pagination-next.s-pagination-disabled) is assigned to the list element where the button is located:
The stop condition for the scraper will be the following javascript snippet:
document.querySelector('.s-pagination-item.s-pagination-next.s-pagination-disabled') !== null
Now it's time to prepare the request that will scrape all products that the search page returned.
The following examples will show how to scrape 3 pages of products from Amazon.com
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.amazon.com/s?k=luminox+watches",
"real_browser": true,
"premium_proxy": "us",
"merge_loops": true,
"scenario": [
{
"loop" : [
{ "wait_for": "[data-component-type=s-search-result]" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector('.s-pagination-next').click()" }
],
"stop_condition": "document.querySelector('.s-pagination-item.s-pagination-next.s-pagination-disabled') !== null",
"iterations": 3
}
],
"parse": {
"watches": [
{
"_parent": "[data-component-type='s-search-result']",
"title": "h2 >> text",
"link": ".a-link-normal >> href",
"price": ".a-price-whole >> text",
"stars": ".a-icon-alt >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
# The following example will show how to scrape 3 pages of products from Amazon.com
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.amazon.com/s?k=luminox+watches",
real_browser: true,
premium_proxy: "us",
merge_loops: true,
scenario: [
{
loop: [
{ wait_for: "[data-component-type=s-search-result]" },
{ execute: "parse" },
{ execute_js: "document.querySelector('.s-pagination-next').click()" }
],
stop_condition: "document.querySelector('.s-pagination-item.s-pagination-next.s-pagination-disabled') !== null",
iterations: 3
}
],
parse: {
watches: [
{
_parent: "[data-component-type=s-search-result]",
title: "h2 >> text",
link: ".a-link-normal >> href",
price: ".a-price-whole >> text",
stars: ".a-icon-alt >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"api_key": "YOUR_PAGE2API_KEY",
"premium_proxy": "us",
"real_browser": true,
"batch": {
"urls": "https://www.amazon.com/s?k=luminox+watches?page=[1, 3, 1]",
"concurrency": 1,
"merge_results": true
},
"parse": {
"watches": [
{
"_parent": "[data-component-type=s-search-result]",
"title": "h2 >> text",
"link": ".a-link-normal >> href",
"price": ".a-price-whole >> text",
"stars": ".a-icon-alt >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
# The following example will show how to scrape 3 pages of products from Amazon.com
payload = {
api_key: 'YOUR_PAGE2API_KEY',
premium_proxy: "us",
real_browser: true,
batch: {
urls: "https://www.amazon.com/s?k=luminox+watches?page=[1, 3, 1]",
concurrency: 1,
merge_results: true
},
parse: {
watches: [
{
_parent: "[data-component-type=s-search-result]",
title: "h2 >> text",
link: ".a-link-normal >> href",
price: ".a-price-whole >> text",
stars: ".a-icon-alt >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"watches": [
{
"title": "Men's Luminox Leatherback Sea Turtle 44mm Watch",
"link": "https://www.amazon.com/Luminox-Leatherback-Turtle-Giant-Black/dp/B07CVFWXMR/ref=sr_1_2?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-2",
"price": "$223.47",
"stars": "4.5 out of 5 stars"
},
{
"title": "The Original Navy Seal Mens Watch Black Display (XS.3001.F/Navy Seal Series): 200 Meter Water Resistant + Light Weight Case + Constant Night Visibility",
"link": "https://www.amazon.com/Luminox-Wrist-Watch-Navy-Original/dp/B07NYXV77C/ref=sr_1_3?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-3",
"price": "$254.12",
"stars": "4.3 out of 5 stars"
},
{
"title": "Leatherback SEA Turtle Giant - 0323",
"link": "https://www.amazon.com/Luminox-Leatherback-SEA-Turtle-Giant/dp/B07PBC31N8/ref=sr_1_4?dchild=1&keywords=luminox+watches&qid=1634327863&sr=8-4",
"price": "$179.00",
"stars": "4.3 out of 5 stars"
},
...
]
},
...
}
How to scrape Amazon reviews
First what we need is to click on the See all reviews link from the Product page.
https://www.amazon.com/product-reviews/B072FNJLBC
The URL is the first parameter we need to perform the reviews scraping.
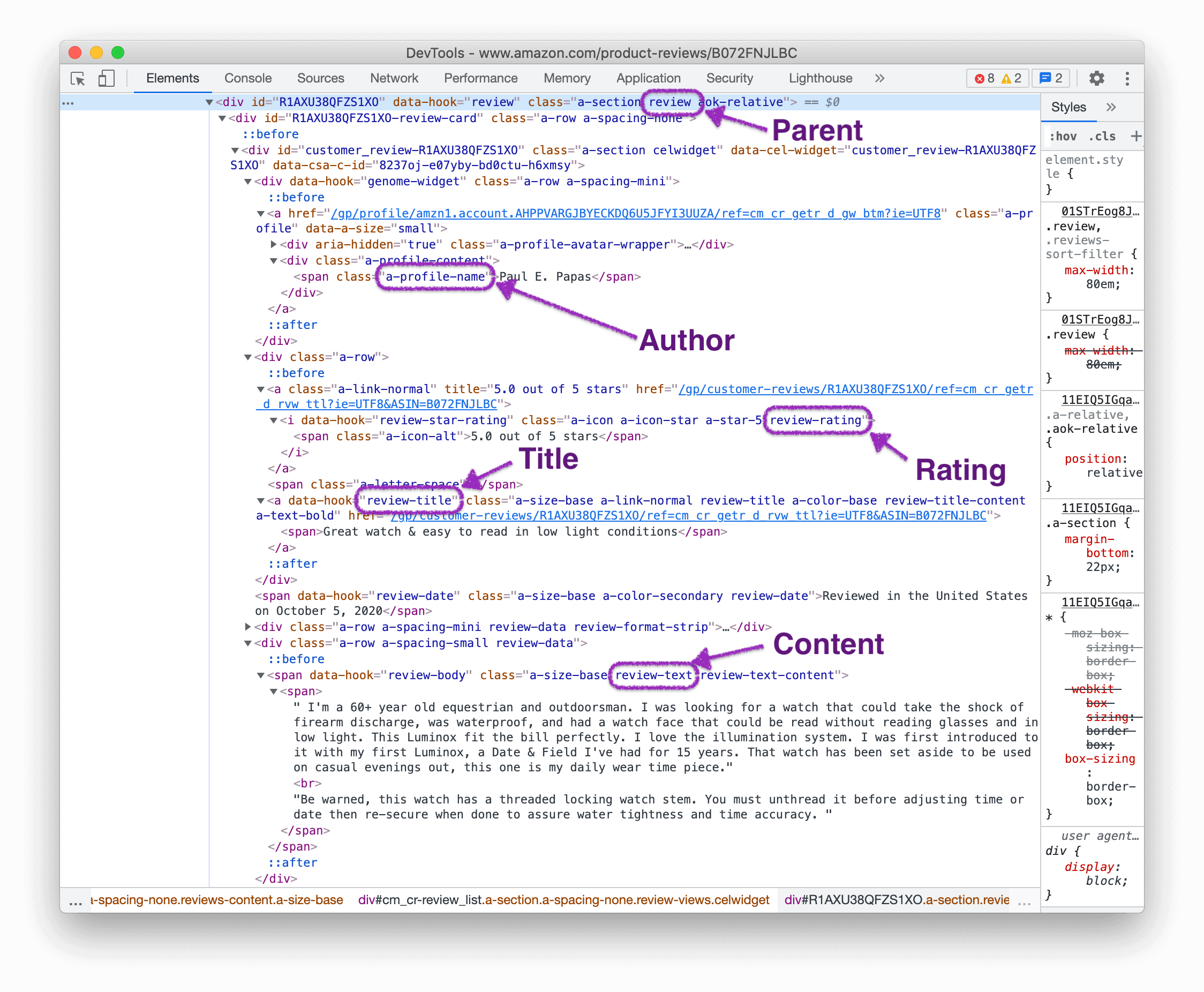
The HTML from a single review will look like this:
Luckily, the pagination handling is similar to the one described above, so we will use the same flow.
Now it's time to prepare the request that will scrape all reviews.
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.amazon.com/product-reviews/B072FNJLBC",
"real_browser": true,
"premium_proxy": "us",
"merge_loops": true,
"scenario": [
{
"loop" : [
{ "wait_for": ".a-pagination li.a-last" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector('.a-pagination li.a-last a').click()" }
],
"stop_condition": "document.querySelector('.a-last.a-disabled') !== null"
}
],
"parse": {
"reviews": [
{
"_parent": "[data-hook='review']",
"title": ".review-title >> text",
"author": ".a-profile-name >> text",
"stars": ".review-rating >> text",
"content": ".review-text >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
# The following example will show how to scrape multiple pages of reviews from Amazon.com
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.amazon.com/product-reviews/B072FNJLBC",
real_browser: true,
premium_proxy: "us",
merge_loops: true,
scenario: [
{
loop: [
{ wait_for: "[data-hook=review]" },
{ execute: "parse" },
{ execute_js: "document.querySelector('.a-pagination li.a-last a').click()" }
],
stop_condition: "document.querySelector('.a-last.a-disabled') !== null"
}
],
"parse": {
"reviews": [
{
_parent: "[data-hook=review]",
title: ".review-title >> text",
author: ".a-profile-name >> text",
stars: ".review-rating >> text",
content: ".review-text >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"api_key": "YOUR_PAGE2API_KEY",
"real_browser": true,
"premium_proxy": "us",
"batch": {
"urls": "https://www.amazon.com/product-reviews/B072FNJLBC/?pageNumber=[1, 3, 1]",
"concurrency": 1,
"merge_results": true
},
"parse": {
"reviews": [
{
"_parent": "[data-hook=review]",
"title": ".review-title >> text",
"author": ".a-profile-name >> text",
"stars": ".review-rating >> text",
"content": ".review-text >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
# The following example will show how to scrape 3 pages of reviews from Amazon.com
payload = {
api_key: 'YOUR_PAGE2API_KEY',
real_browser: true,
premium_proxy: "us",
batch: {
urls: "https://www.amazon.com/product-reviews/B072FNJLBC/?pageNumber=[1, 3, 1]",
concurrency: 1,
merge_results: true
},
parse: {
reviews: [
{
_parent: "[data-hook=review]",
title: ".review-title >> text",
author: ".a-profile-name >> text",
stars: ".review-rating >> text",
content: ".review-text >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"reviews": [
{
"title": "Great watch & easy to read in low light conditions",
"author": "Paul E. Papas",
"stars": "5.0 out of 5 stars",
"content": "I'm a 60+ year old equestrian and outdoorsman. I was looking for a watch that could take the shock of firearm discharge ..."
},
{
"title": "Not Water Resistant, impossible to get amazon help",
"author": "Benjamin H. Curry",
"stars": "2.0 out of 5 stars",
"content": "This watch has a 2 year warranty from date of purchase however after not even on full year my adult son went swimming with it ..."
},
...
]
},
...
}
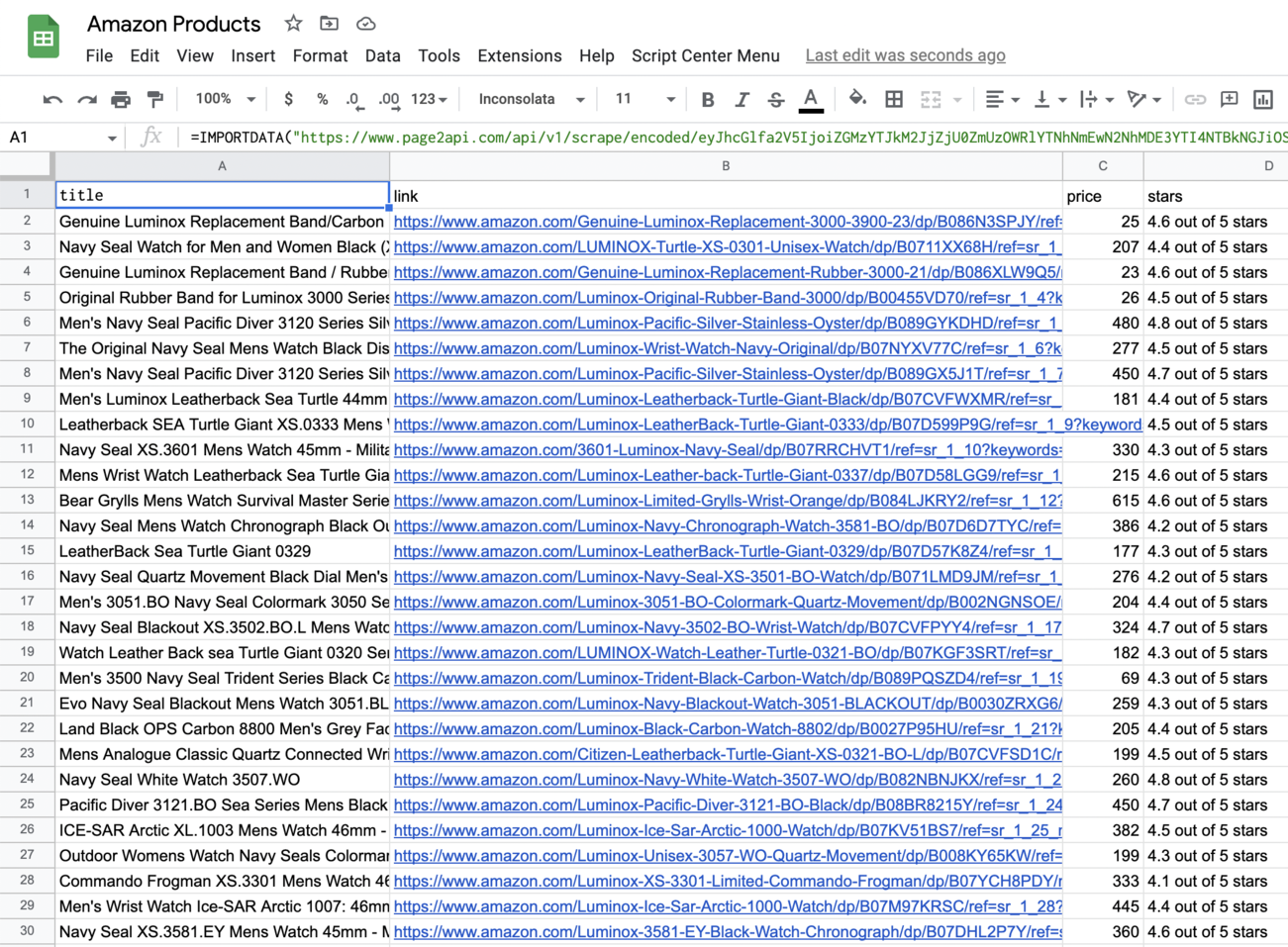
How to export Amazon products to Google Sheets
In order to be able to export our Amazon products to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "watches", "format": "csv"
}
Please note that the batch URLs are defined explicitly to make it simpler to edit the payload.
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
Conclusion
That's pretty much of it!
As we've previously mentioned, Amazon.com is a website that is pretty easy to scrape if you have the right tools.
This is the place where Page2API shines, making web scraping super easy and fun.
