
Introduction
In this blog post, we'll explore the wasiest way to scrape and download a transcript from Youtube for free.For this task, we will use Node.js and a browser library called puppeteer.
The code will launch a browser instance that will open the Youtube video URL and scrape the transcript which you will be able to save on your local machine.
You can use the code from this post to start building your own Youtube transcript downloader.
Prerequisites
To start downloading the transcripts from Youtube, you will need the following things:- Node.js installed on your local machine
- Some basic HTML and JavaScript coding skills.
How to Scrape Youtube Transcript
Before starting, you need to open the URL of a Youtube video that is publicly available and not age-restricted.We will use the following URL:
https://www.youtube.com/watch?v=1WOQumXj0kg
The page will look like the following one:
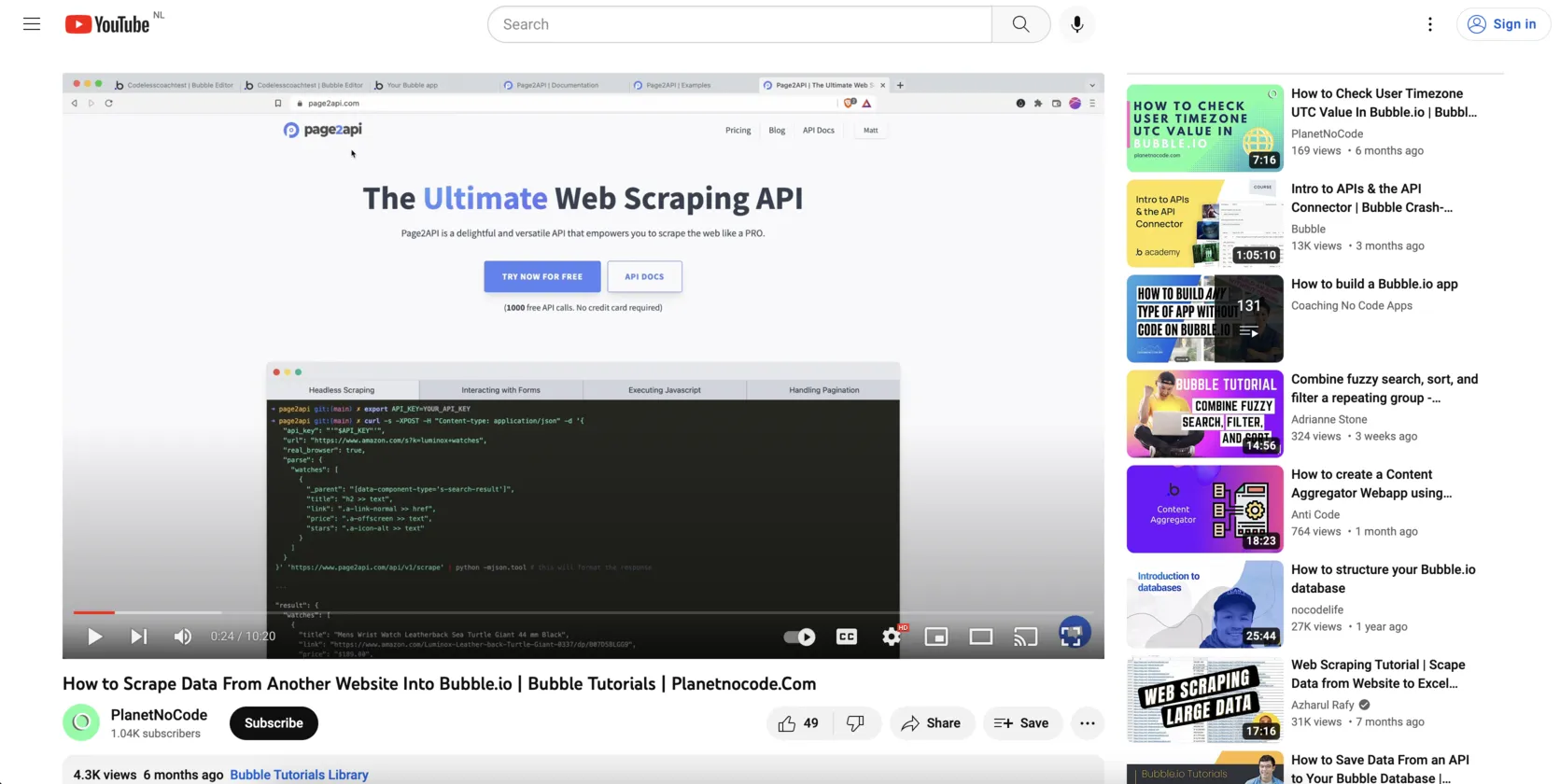
If you are from EU, a Cookie banner will be shown.
To close it programatically, you need to run the following JavaScript snippet:
document.querySelector('button[aria-label*=cookies]')?.click()
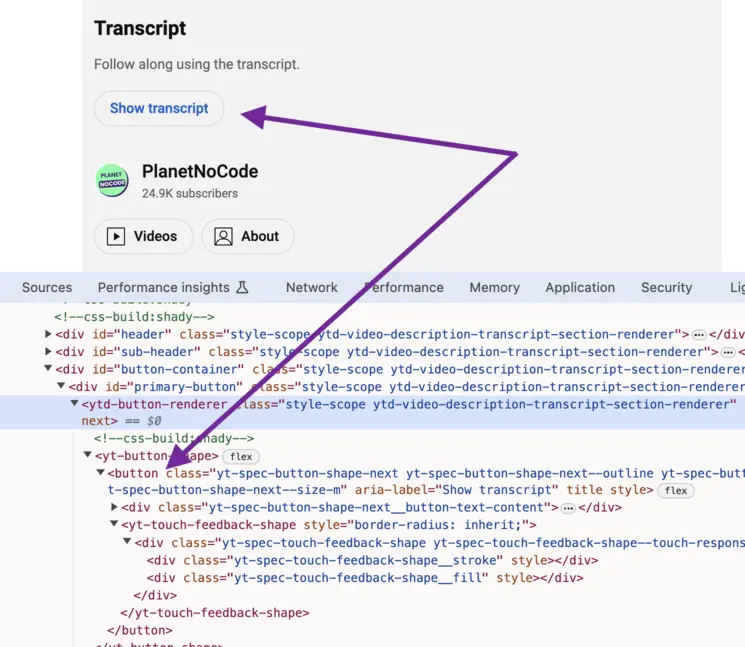
The next step is locating the Show transcript button and clicking it.
To do this programatically, you need to run the following JavaScript snippet:
document.querySelector('ytd-video-description-transcript-section-renderer button').click()
Within a second, the transcript will be shown in the sidebar:
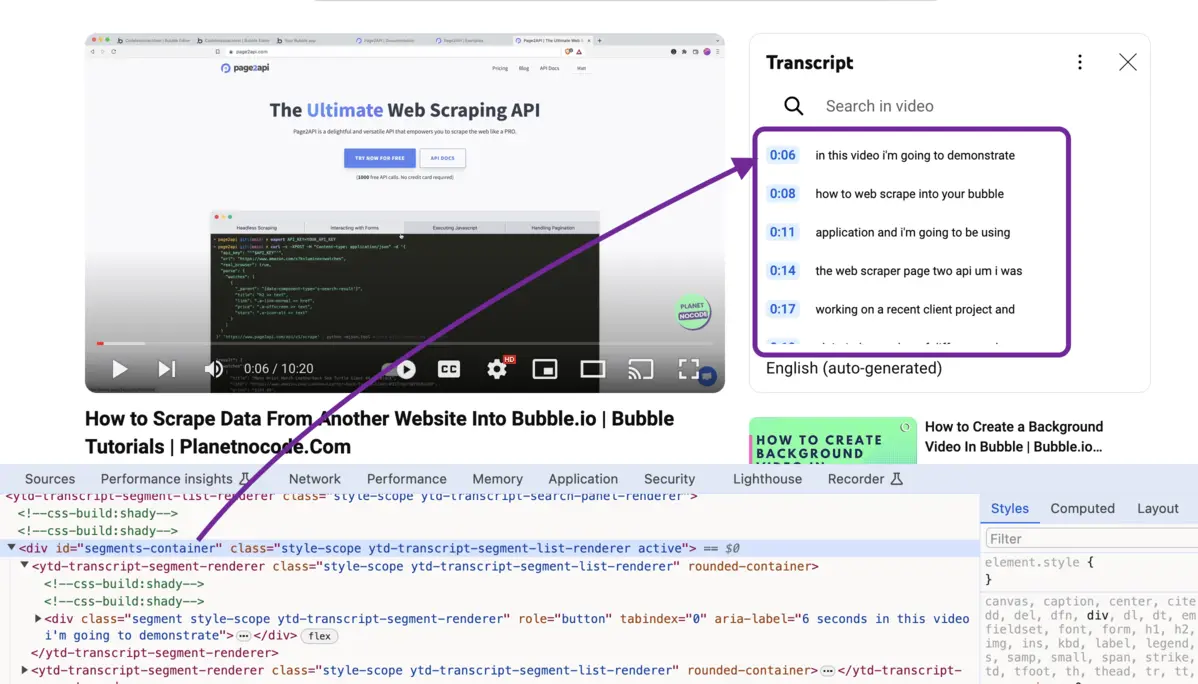
To collect the text nodes that contain the transcript, you need to run this JavaScript snippet:
Array.from(document.querySelectorAll('#segments-container yt-formatted-string')).map(
element => element.textContent?.trim()
).join("\n");
It will generate a text that contains each line from the transcript, joined with a new line:
in this video i'm going to demonstrate
how to web scrape into your bubble
application and i'm going to be using
the web scraper page two api um i was
working on a recent client project and
uh i tried a number of different web
...
How to Download the Youtube Transcript with puppeteer
In this part we will write some Node.js code that will make it possible to download the Youtube transcript.Before we start, we need to make sure that Node.js is installed.
If you are using macOS, you probably have installed Homebrew which makes things a little bit easier:
brew install node
Now we need to create a new folder for our project: youtube-transcript:
mkdir youtube-transcript && cd youtube-transcript
In this folder we will create the package.json file which will contain the information about our project:
{
"name": "transcript",
"version": "1.0.0",
"description": "Youtube transcript parser",
"main": "index.js",
"scripts": {
"start": "npx functions-framework --target=run",
"postinstall": "npx puppeteer browsers install chrome"
},
"author": "Your Name",
"license": "ISC",
"dependencies": {
"puppeteer": "^22.6.0",
"puppeteer-extra": "^3.3.6",
"puppeteer-extra-plugin-stealth": "^2.11.2"
}
}
The next step is installing all the needed packages:
npm install
Now let's create the index.js file and start putting all the things together.
const puppeteer = require('puppeteer-extra')
const StealthPlugin = require('puppeteer-extra-plugin-stealth')
// using the stealth plugin to avoid being detected during scraping
puppeteer.use(StealthPlugin())
// this is the main function
const run = async(req, res) => {
const browser = await puppeteer.launch({
headless: "new",
ignoreDefaultArgs: ["--enable-automation"]
}); // Starting the headless browser (Chrome)
const page = await browser.newPage();
let result = null;
const url = process.argv[2] // reading the URL
try {
await page.goto(url, { waitUntil: 'domcontentloaded' }); // opening the youtube URL
await page.evaluate(() => {
document.querySelector('button[aria-label*=cookies]')?.click() // closing the Cookie banner
});
await page.waitForSelector("ytd-video-description-transcript-section-renderer button", {
timeout: 10_000
}) // waiting max 10 seconds for the 'Show transcript' button to appear
await page.evaluate(() => {
document.querySelector('ytd-video-description-transcript-section-renderer button').click()
}) // clicking on the 'Show transcript' button
result = await parseTranscript(page); // parsing the transcript
await page.close()
await browser.close()
console.log(result) // returning the transcript
} catch(error) {
console.log(error)
await page.close()
await browser.close()
}
}
// this function will parse the transcript
const parseTranscript = async(page) => {
// waiting max 10 seconds for the transcript container to appear
await page.waitForSelector('#segments-container', {
timeout: 10_000
});
// parsing all the text nodes from the transcript container and join them with an empty line
return page.evaluate(() => {
return Array.from(document.querySelectorAll('#segments-container yt-formatted-string')).map(
element => element.textContent?.trim()
).join("\n");
});
}
run()
To run this script, execute the following command:
node index.js https://www.youtube.com/watch?v=1WOQumXj0kg
The result will look like the following one:
in this video i'm going to demonstrate
how to web scrape into your bubble
application and i'm going to be using
the web scraper page two api um i was
working on a recent client project and
uh i tried a number of different web
scraper apis and i found that page two
api uh offered the best integration for
what i was trying to do
with the bubble api connector plug-in
so that's what i'll be demonstrating uh
to you now um so uh if we head into
the bubble api connector install this
plug-in if you haven't already by bubble
and we'll add another api
...
And if you want to save the transcript to a text file, execute the following command:
node index.js https://www.youtube.com/watch?v=1WOQumXj0kg > transcript.txt
Conclusion
And there you have it—a simple yet effective way to download YouTube transcripts using Puppeteer!This script demonstrates how we can leverage the power of automation to access and extract information from web pages, even when it involves interacting with elements like buttons and waiting for specific content to appear.
Remember, the core of this script utilizes Puppeteer's ability to simulate a real user's interactions, allowing us to navigate through pages, accept cookies, click on elements, and scrape the content we need. With the stealth plugin, we reduce the chances of being detected as a bot, making our scraping activities more seamless and efficient.
I hope this tutorial has demystified the process of web scraping with Puppeteer and shown you that with a bit of JavaScript, you can unlock a vast amount of data available on the web. Feel free to tweak this script to suit your needs—maybe you want to download transcripts from a list of URLs or incorporate additional data into your results.
Happy coding, and may your curiosity lead you to amazing projects!
