
Introduction
YouTube is a video sharing service where users can watch, like, share, comment and upload their own videos.
In this article, you will read about the easiest way to web scrape Youtube data with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Youtube channel videos into Google Sheets.
In this article, we will learn how to:
Prerequisites
To start scraping Youtube, you will need the following things:
- A Page2API account
- A Youtube channel you want to scrape, for example PlanetNoCode
- A Youtube video you want to scrape, in our case it will be the video that explains how to scrape data from another website into Bubble.io with Page2API
How to scrape Youtube Video Details
The first thing you need is to open the youtube video we are interested in.
https://www.youtube.com/watch?v=1WOQumXj0kg
The page will look like the following one:
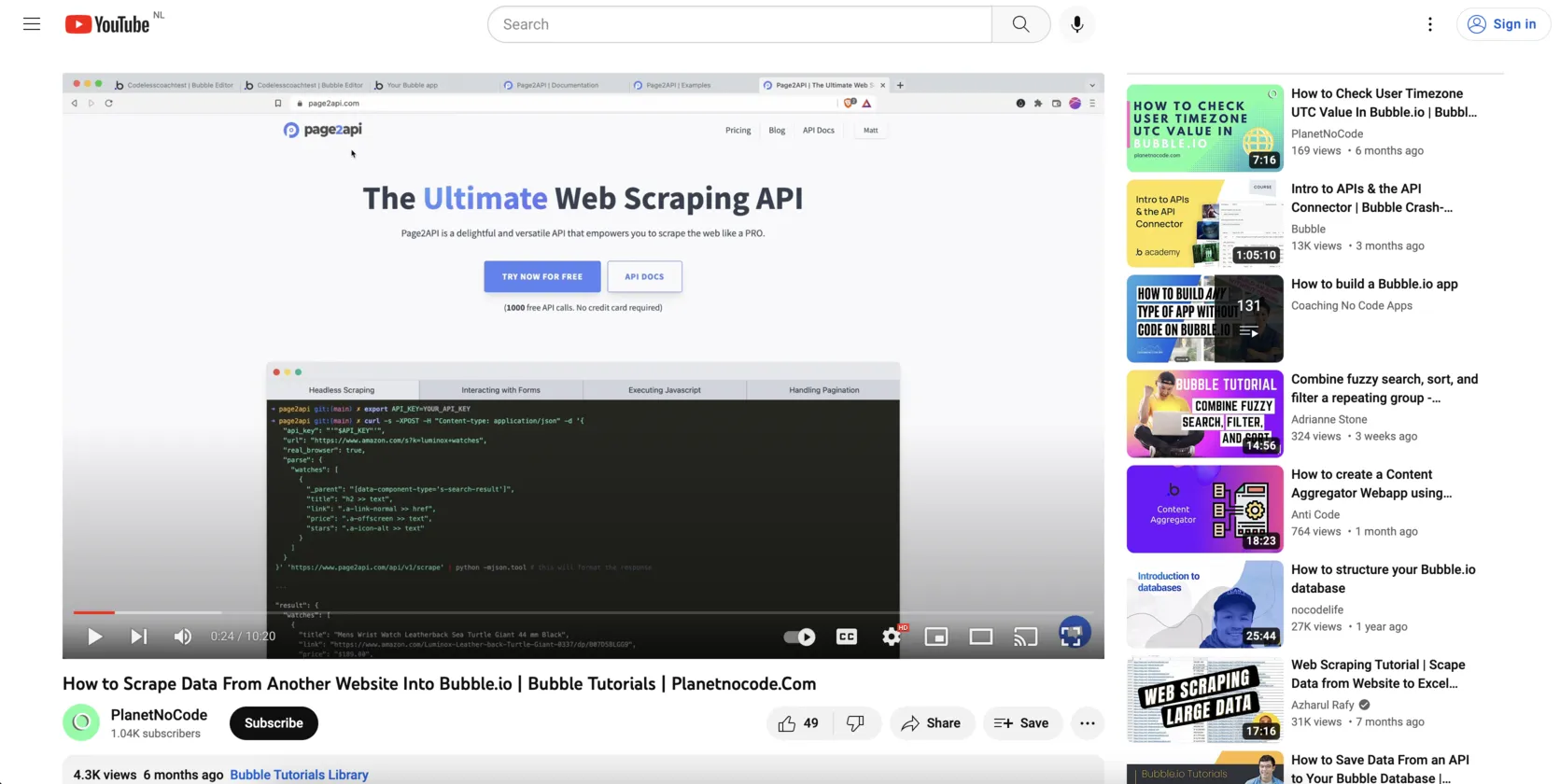
From this page, we will scrape the following attributes:
- Title
- Likes
- Views
- Uploaded
- Channel name
- Channel URL
- Channel subsccribers
Let's define the selectors for each attribute.
Youtube Video Details selectors
/* Title: */
meta[name=title]
/* Likes: */
like-button-view-model span[role=text]
/* Views: */
.ytd-watch-metadata span[dir=auto]:nth-of-type(1)
/* Uploaded: */
.ytd-watch-metadata span[dir=auto]:nth-of-type(3)
/* Channel name: */
.ytd-channel-name a
/* Channel URL: */
.ytd-channel-name a
/* Channel subscribers: */
#owner-sub-count
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.youtube.com/watch?v=1WOQumXj0kg",
"real_browser": true,
"premium_proxy": "us",
"wait_for": "like-button-view-model",
"parse": {
"title": "meta[name=title] >> content",
"likes": "like-button-view-model >> text",
"views": ".ytd-watch-metadata span[dir=auto]:nth-of-type(1) >> text",
"uploaded": ".ytd-watch-metadata span[dir=auto]:nth-of-type(3) >> text",
"channel_name": ".ytd-channel-name a >> text",
"channel_url": ".ytd-channel-name a >> href",
"channel_subscribers": "#owner-sub-count >> text"
}
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
url: "https://www.youtube.com/watch?v=1WOQumXj0kg",
real_browser: true,
premium_proxy: "us",
wait_for: "like-button-view-model",
parse: {
title: "meta[name=title] >> content",
likes: "like-button-view-model >> text",
views: ".ytd-watch-metadata span[dir=auto]:nth-of-type(1) >> text",
uploaded: ".ytd-watch-metadata span[dir=auto]:nth-of-type(3) >> text",
channel_name: ".ytd-channel-name a >> text",
channel_url: ".ytd-channel-name a >> href",
channel_subscribers: "#owner-sub-count >> text"
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
print(result)
{
"result": {
"title": "How to Scrape Data From Another Website Into Bubble.io | Bubble Tutorials | Planetnocode.Com",
"likes": "49",
"views": "4.3K views",
"uploaded": "6 months ago",
"channel_name": "PlanetNoCode",
"channel_url": "https://www.youtube.com/@planetnocode9104",
"channel_subscribers": "1.04K subscribers"
} ...
}
How to scrape Youtube Channel Details
First, we need to open the Youtube and search for the desired channel.
https://www.youtube.com/@planetnocode9104
The page we see must look similar to the following one:
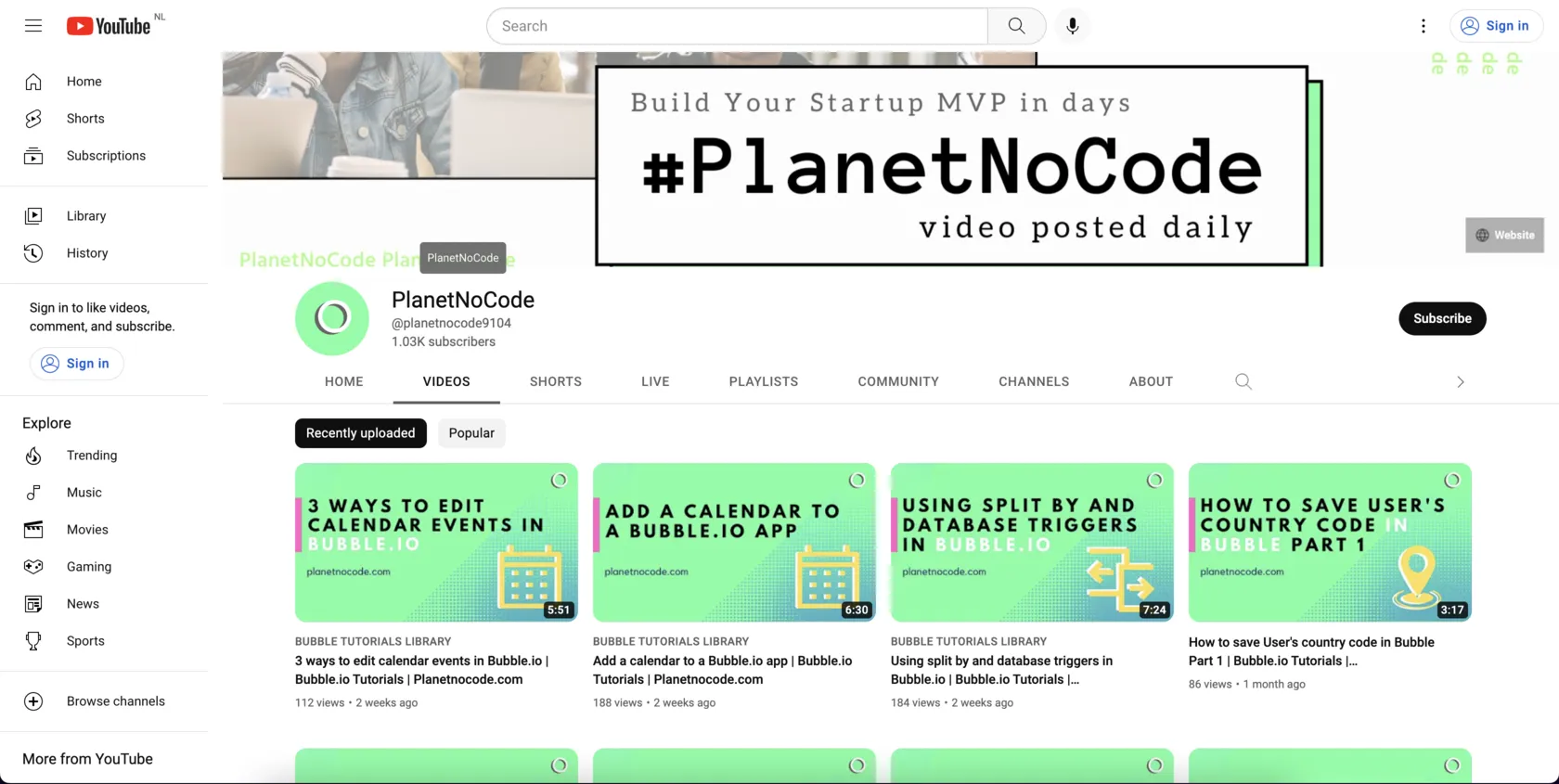
From this page, we will scrape the following attributes:
Channel Details
- Title
- Subscribers
- Thumbnail
Latest videos
- Title
- Badge
- URL
- Views
- Uploaded
Channel details selectors
/* Title: */
#text-container .ytd-channel-name
/* Subscribers: */
#subscriber-count
/* Thumbnail: */
img#img
Latest videos selectors
/* Parent: */
#content.style-scope.ytd-rich-item-renderer
/* Title: */
#video-title
/* Badge: */
.badge
/* URL: */
a#thumbnail
/* Views: */
#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(1)
/* Uploaded: */
#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(2)
Now, let's handle the pagination.
document.querySelectorAll("#content.style-scope.ytd-rich-item-renderer").forEach(e => e.scrollIntoView({behavior: 'smooth'}))
Now let's build the request that will scrape all videos that the Youtube channel page returned.
The following examples will show how to scrape 2 pages of videos from Youtube's channel page.
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.youtube.com/@planetnocode9104/videos",
"real_browser": true,
"premium_proxy": "us",
"parse": {
"title": "#text-container .ytd-channel-name >> text",
"subscribers": "#subscriber-count >> text",
"thumbnail": "img#img >> src",
"latest_videos": [
{
"_parent": "#content.style-scope.ytd-rich-item-renderer",
"badge": ".badge >> text",
"title": "#video-title >> text",
"url": "a#thumbnail >> href",
"views": "#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(1) >> text",
"uploaded": "#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(2) >> text"
}
]
},
"scenario": [
{ "wait_for": "#text-container .ytd-channel-name" },
{
"loop": [
{ "execute_js": "document.querySelectorAll('#content.style-scope.ytd-rich-item-renderer').forEach(e => e.scrollIntoView({behavior: 'smooth'}))" },
{ "wait": 1 }
],
"iterations": 2
},
{ "execute": "parse" }
]
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
url: "https://www.youtube.com/@planetnocode9104/videos",
real_browser: true,
premium_proxy: "us",
parse: {
title: "#text-container .ytd-channel-name >> text",
subscribers: "#subscriber-count >> text",
thumbnail: "img#img >> src",
latest_videos: [
{
_parent: "#content.style-scope.ytd-rich-item-renderer",
badge: ".badge >> text",
title: "#video-title >> text",
url: "a#thumbnail >> href",
views: "#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(1) >> text",
uploaded: "#metadata-line .inline-metadata-item.style-scope.ytd-video-meta-block:nth-of-type(2) >> text"
}
]
},
scenario: [
{ wait_for: "#text-container .ytd-channel-name" },
{
loop: [
{ execute_js: "document.querySelectorAll('#content.style-scope.ytd-rich-item-renderer').forEach(e => e.scrollIntoView({behavior: 'smooth'}))" },
{ wait: 1 }
],
iterations: 2
},
{ execute: "parse" }
]
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"title": "PlanetNoCode",
"subscribers": "1.05K subscribers",
"thumbnail": "https://yt3.googleusercontent.com/eZ2I1ah_TfO4Go8oagPCmbwSdplTY6O0663Yjxney_fpBLngPJD6nN3fMrAb_OBMjQABY2vBxg=s88-c-k-c0x00ffffff-no-rj",
"latest_videos": [
{
"badge": "Bubble Tutorials Library",
"title": "3 ways to edit calendar events in Bubble.io | Bubble.io Tutorials | Planetnocode.com",
"url": "https://www.youtube.com/watch?v=1RGgw0lSPM0",
"views": "149 views",
"uploaded": "2 weeks ago"
},
{
"badge": "Bubble Tutorials Library",
"title": "Add a calendar to a Bubble.io app | Bubble.io Tutorials | Planetnocode.com",
"url": "https://www.youtube.com/watch?v=LpoUBqUiXkc",
"views": "212 views",
"uploaded": "3 weeks ago"
},
{
"badge": "Bubble Tutorials Library",
"title": "Using split by and database triggers in Bubble.io | Bubble.io Tutorials | Planetnocode.com",
"url": "https://www.youtube.com/watch?v=0XR9YA1n2cQ",
"views": "199 views",
"uploaded": "3 weeks ago"
},
}, ...
}
How to export Youtube channel videos to Google Sheets
In order to be able to export the videos to a Google Spreadsheet we will need to slightly modify and simplify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "videos", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
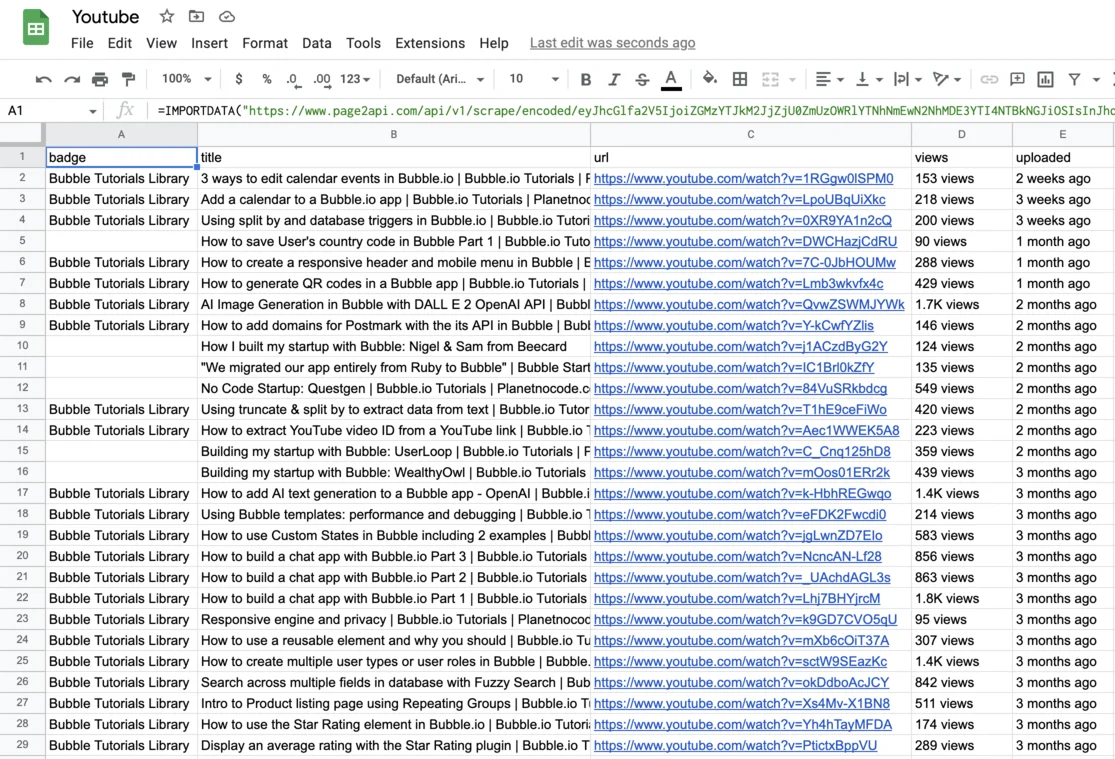
Final thoughts
Collecting the data from Youtube manually can be a bit overwhelming and hard to scale.
However, a Web Scraping API can easily help you overcome this challenge and perform Youtube scraping in no time.
With Page2API you can quickly get access to the data you need, and use the time you saved on more important things!
