
Introduction
Yellow Pages is a online directory that helps you connect instantly with great local businesses.
You can find over 20 million business listings, browse menus, search by cuisine, book a table, see showtimes, find cheap gas, and navigate with maps.
In this article, you will read about the easiest way to scrape Yellow Pages data with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Yellow Pages data into Google Sheets.
You can scrape data from Yellow Pages, that will contain such information as business names, phone numbers, addresses, ratings, and more.
In this article, we will learn how to:
- Scrape Yellow Pages data
- Export Yellow Pages data to Google Sheets
Prerequisites
To start scraping Yellow Pages, you will need the following things:
- A Page2API account
- A category and a location, in which we want to search for listings. Let's search for 'Restaurants, Miami'.
How to scrape Yellow Pages data
First, we need to open the Yellow Pages search page and set the filters we need.
https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami
The page we see must look similar to the following one:
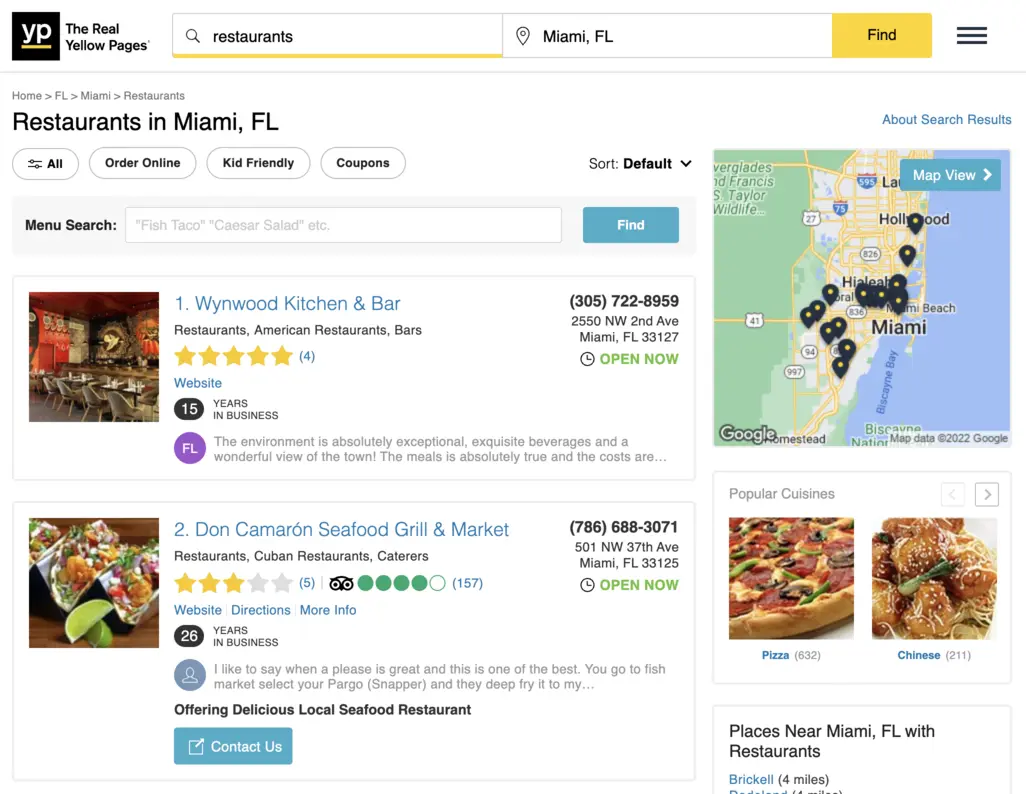
From the search page, we will scrape the following attributes:
- Title
- URL
- Website
- Phone
- Street
- Locality
- Categories
- Snippet
- Internal rating
- Internal rating count
- Tripadvisor rating
- Tripadvisor rating count
Now, let's define the selectors for each attribute.
/* Parent: */
div.result
/* Title: */
.business-name
/* URL: */
.business-name
/* Website: */
.track-visit-website
/* Phone: */
.phone
/* Street: */
.street-address
/* Locality: */
.locality
/* Categories: */
.categories a
/* Snippet: */
.snippet
/* Internal rating: */
.rating .result-rating
/* Internal rating count: */
.rating .count
/* Tripadvisor rating: */
.ta-rating
/* Tripadvisor rating count: */
.ta-count
In order to collect all the ratings - we must run the JS snippet below:
/* convert tripadvisor rating value */
document.querySelectorAll(".ta-rating").forEach(function(e) {
let ta_rating = e.attributes.class.value.trim().split(/\s+/).reverse()[0].replace("ta-", "").replace("-", ".");
e.dataset.ta_rating = ta_rating;
});
/* convert tripadvisor rating count */
document.querySelectorAll(".ta-count").forEach(function(e) {
let ta_count = e.textContent.replace(/[\(\)]+/g, "");
e.dataset.ta_count = ta_count;
});
/* convert internal rating value */
document.querySelectorAll(".rating .result-rating").forEach(function(e) {
let internal_rating_word = e.attributes.class.value.replace("result-rating", "").trim().replace(" ", "-");
let rating_mapping = {
"one": 1, "one-half": 1.5, "two": 2, "two-half": 2.5, "three": 3, "three-half": 3.5, "four": 4, "four-half": 4.5, "five": 5
}
e.dataset.internal_rating = rating_mapping[internal_rating_word];
});
/* convert internal rating count */
document.querySelectorAll(".rating .count").forEach(function(e) {
let extra_count = e.textContent.replace(/[\(\)]+/g, "");
e.dataset.internal_rating_count = extra_count;
});
Let's convert that snippet to base64:
ICAgIC8qIGNvbnZlcnQgdHJpcGFkdmlzb3IgcmF0aW5nIHZhbHVlICovCgogICAgZG9jdW1lbnQucXVlcnlTZWxlY3RvckFsbCgiLnRhLXJhdGluZyIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfcmF0aW5nID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnRyaW0oKS5zcGxpdCgvXHMrLykucmV2ZXJzZSgpWzBdLnJlcGxhY2UoInRhLSIsICIiKS5yZXBsYWNlKCItIiwgIi4iKTsKICAgICAgZS5kYXRhc2V0LnRhX3JhdGluZyA9IHRhX3JhdGluZzsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IHRyaXBhZHZpc29yIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi50YS1jb3VudCIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfY291bnQgPSBlLnRleHRDb250ZW50LnJlcGxhY2UoL1tcKFwpXSsvZywgIiIpOwogICAgICBlLmRhdGFzZXQudGFfY291bnQgPSB0YV9jb3VudDsKICAgIH0pOwogICAgCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyB2YWx1ZSAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLnJlc3VsdC1yYXRpbmciKS5mb3JFYWNoKGZ1bmN0aW9uKGUpIHsKICAgICAgbGV0IGludGVybmFsX3JhdGluZ193b3JkID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnJlcGxhY2UoInJlc3VsdC1yYXRpbmciLCAiIikudHJpbSgpLnJlcGxhY2UoIiAiLCAiLSIpOwogICAgICBsZXQgcmF0aW5nX21hcHBpbmcgPSB7CiAgICAgICAgIm9uZSI6IDEsICJvbmUtaGFsZiI6IDEuNSwgInR3byI6IDIsICJ0d28taGFsZiI6IDIuNSwgInRocmVlIjogMywgInRocmVlLWhhbGYiOiAzLjUsICJmb3VyIjogNCwgImZvdXItaGFsZiI6IDQuNSwgImZpdmUiOiA1CiAgICAgIH0KICAgICAgZS5kYXRhc2V0LmludGVybmFsX3JhdGluZyA9IHJhdGluZ19tYXBwaW5nW2ludGVybmFsX3JhdGluZ193b3JkXTsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLmNvdW50IikuZm9yRWFjaChmdW5jdGlvbihlKSB7CiAgICAgIGxldCBleHRyYV9jb3VudCA9IGUudGV4dENvbnRlbnQucmVwbGFjZSgvW1woXCldKy9nLCAiIik7CiAgICAgIGUuZGF0YXNldC5pbnRlcm5hbF9yYXRpbmdfY291bnQgPSBleHRyYV9jb3VudDsKICAgIH0pOw==
Now, let's handle the pagination.
// Page 1
https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=1
// Page 2
https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=2
// Page 3
https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=3
This looks like a great scenario to use the batch scraping approach.
Now let's build the request that will scrape all listings that the search page returned.
The following examples will show how to scrape 3 pages of listings from Yellowpages.com
{
"api_key": "YOUR_PAGE2API_KEY",
"batch": {
"urls": "https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=[1, 3, 1]",
"concurrency": 1,
"merge_results": true
},
"real_browser": true,
"scenario": [
{ "wait": 5 },
{ "execute_js": "ICAgIC8qIGNvbnZlcnQgdHJpcGFkdmlzb3IgcmF0aW5nIHZhbHVlICovCgogICAgZG9jdW1lbnQucXVlcnlTZWxlY3RvckFsbCgiLnRhLXJhdGluZyIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfcmF0aW5nID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnRyaW0oKS5zcGxpdCgvXHMrLykucmV2ZXJzZSgpWzBdLnJlcGxhY2UoInRhLSIsICIiKS5yZXBsYWNlKCItIiwgIi4iKTsKICAgICAgZS5kYXRhc2V0LnRhX3JhdGluZyA9IHRhX3JhdGluZzsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IHRyaXBhZHZpc29yIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi50YS1jb3VudCIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfY291bnQgPSBlLnRleHRDb250ZW50LnJlcGxhY2UoL1tcKFwpXSsvZywgIiIpOwogICAgICBlLmRhdGFzZXQudGFfY291bnQgPSB0YV9jb3VudDsKICAgIH0pOwogICAgCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyB2YWx1ZSAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLnJlc3VsdC1yYXRpbmciKS5mb3JFYWNoKGZ1bmN0aW9uKGUpIHsKICAgICAgbGV0IGludGVybmFsX3JhdGluZ193b3JkID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnJlcGxhY2UoInJlc3VsdC1yYXRpbmciLCAiIikudHJpbSgpLnJlcGxhY2UoIiAiLCAiLSIpOwogICAgICBsZXQgcmF0aW5nX21hcHBpbmcgPSB7CiAgICAgICAgIm9uZSI6IDEsICJvbmUtaGFsZiI6IDEuNSwgInR3byI6IDIsICJ0d28taGFsZiI6IDIuNSwgInRocmVlIjogMywgInRocmVlLWhhbGYiOiAzLjUsICJmb3VyIjogNCwgImZvdXItaGFsZiI6IDQuNSwgImZpdmUiOiA1CiAgICAgIH0KICAgICAgZS5kYXRhc2V0LmludGVybmFsX3JhdGluZyA9IHJhdGluZ19tYXBwaW5nW2ludGVybmFsX3JhdGluZ193b3JkXTsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLmNvdW50IikuZm9yRWFjaChmdW5jdGlvbihlKSB7CiAgICAgIGxldCBleHRyYV9jb3VudCA9IGUudGV4dENvbnRlbnQucmVwbGFjZSgvW1woXCldKy9nLCAiIik7CiAgICAgIGUuZGF0YXNldC5pbnRlcm5hbF9yYXRpbmdfY291bnQgPSBleHRyYV9jb3VudDsKICAgIH0pOw==" },
{ "execute": "parse" }
],
"parse": {
"listings": [
{
"_parent": "div.result",
"title": ".business-name >> text",
"url": ".business-name >> href",
"phone": ".phone >> text",
"street": ".street-address >> text",
"locality": ".locality >> text",
"website": ".track-visit-website >> href",
"categories": [".categories a >> text"],
"snippet": ".snippet >> text",
"internal_rating": ".rating .result-rating >> data-internal_rating",
"internal_rating_count": ".rating .count >> data-internal_rating_count",
"tripadvisor_rating": ".ta-rating >> data-ta_rating",
"tripadvisor_rating_count": ".ta-count >> data-ta_count"
}
]
}
}
{
"api_key": "YOUR_PAGE2API_KEY",
"batch": {
"urls": "https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=[1, 3, 1]",
"concurrency": 1,
"merge_results": true
},
"parse": {
"listings": [
{
"_parent": "div.result",
"title": ".business-name >> text",
"url": ".business-name >> href",
"phone": ".phone >> text",
"street": ".street-address >> text",
"locality": ".locality >> text",
"website": ".track-visit-website >> href",
"categories": [".categories a >> text"],
"snippet": ".snippet >> text"
}
]
}
}
Worth mentioning: due to the fact that the real browser is not being used - the payload above will run few times faster and consume less credits.
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
batch: {
urls: "https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=Miami&page=[1, 3, 1]",
concurrency: 1,
merge_results: true
},
real_browser: true,
scenario: [
{ wait: 5 },
{ execute_js: "ICAgIC8qIGNvbnZlcnQgdHJpcGFkdmlzb3IgcmF0aW5nIHZhbHVlICovCgogICAgZG9jdW1lbnQucXVlcnlTZWxlY3RvckFsbCgiLnRhLXJhdGluZyIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfcmF0aW5nID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnRyaW0oKS5zcGxpdCgvXHMrLykucmV2ZXJzZSgpWzBdLnJlcGxhY2UoInRhLSIsICIiKS5yZXBsYWNlKCItIiwgIi4iKTsKICAgICAgZS5kYXRhc2V0LnRhX3JhdGluZyA9IHRhX3JhdGluZzsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IHRyaXBhZHZpc29yIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi50YS1jb3VudCIpLmZvckVhY2goZnVuY3Rpb24oZSkgewogICAgICBsZXQgdGFfY291bnQgPSBlLnRleHRDb250ZW50LnJlcGxhY2UoL1tcKFwpXSsvZywgIiIpOwogICAgICBlLmRhdGFzZXQudGFfY291bnQgPSB0YV9jb3VudDsKICAgIH0pOwogICAgCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyB2YWx1ZSAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLnJlc3VsdC1yYXRpbmciKS5mb3JFYWNoKGZ1bmN0aW9uKGUpIHsKICAgICAgbGV0IGludGVybmFsX3JhdGluZ193b3JkID0gZS5hdHRyaWJ1dGVzLmNsYXNzLnZhbHVlLnJlcGxhY2UoInJlc3VsdC1yYXRpbmciLCAiIikudHJpbSgpLnJlcGxhY2UoIiAiLCAiLSIpOwogICAgICBsZXQgcmF0aW5nX21hcHBpbmcgPSB7CiAgICAgICAgIm9uZSI6IDEsICJvbmUtaGFsZiI6IDEuNSwgInR3byI6IDIsICJ0d28taGFsZiI6IDIuNSwgInRocmVlIjogMywgInRocmVlLWhhbGYiOiAzLjUsICJmb3VyIjogNCwgImZvdXItaGFsZiI6IDQuNSwgImZpdmUiOiA1CiAgICAgIH0KICAgICAgZS5kYXRhc2V0LmludGVybmFsX3JhdGluZyA9IHJhdGluZ19tYXBwaW5nW2ludGVybmFsX3JhdGluZ193b3JkXTsKICAgIH0pOwoKCiAgICAvKiBjb252ZXJ0IGludGVybmFsIHJhdGluZyBjb3VudCAqLwoKICAgIGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3JBbGwoIi5yYXRpbmcgLmNvdW50IikuZm9yRWFjaChmdW5jdGlvbihlKSB7CiAgICAgIGxldCBleHRyYV9jb3VudCA9IGUudGV4dENvbnRlbnQucmVwbGFjZSgvW1woXCldKy9nLCAiIik7CiAgICAgIGUuZGF0YXNldC5pbnRlcm5hbF9yYXRpbmdfY291bnQgPSBleHRyYV9jb3VudDsKICAgIH0pOw==" },
{ execute: "parse" }
],
parse: {
listings: [
{
_parent: "div.result",
title: ".business-name >> text",
url: ".business-name >> href",
phone: ".phone >> text",
street: ".street-address >> text",
locality: ".locality >> text",
website: ".track-visit-website >> href",
categories: [".categories a >> text"],
snippet: ".snippet >> text",
internal_rating: ".rating .result-rating >> data-internal_rating",
internal_rating_count: ".rating .count >> data-internal_rating_count",
tripadvisor_rating: ".ta-rating >> data-ta_rating",
tripadvisor_rating_count: ".ta-count >> data-ta_count"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"listings": [
{
"title": "Don Camarón Seafood Grill & Market",
"url": "https://www.yellowpages.com/miami-fl/mip/don-camarn-seafood-grill-market-461615396?lid=1002082255372",
"phone": "(786) 688-3071",
"street": "501 NW 37th Ave",
"locality": "Miami, FL 33125",
"website": "https://www.doncamaronrestaurant.com",
"categories": [
"Restaurants",
"Cuban Restaurants",
"Caterers"
],
"snippet": "I like to say when a please is great and this is one of the best. You go to fish market select your Pargo (Snapper) and they deep fry it to my…",
"internal_rating": "3",
"internal_rating_count": "5",
"tripadvisor_rating": "4.0",
"tripadvisor_rating_count": "157"
},
{
"title": "Steve's Pizza",
"url": "https://www.yellowpages.com/miami-fl/mip/steves-pizza-11223971?lid=1000437162617",
"phone": "(305) 233-4561",
"street": "18063 S Dixie Hwy",
"locality": "Miami, FL 33157",
"website": "https://www.stevespizza.com",
"categories": [
"Restaurants",
"Pizza",
"Take Out Restaurants"
],
"snippet": "Great pizza! Love it! Will continue to go back",
"internal_rating": "4.5",
"internal_rating_count": "27",
"tripadvisor_rating": "4.0",
"tripadvisor_rating_count": "63"
},
...
]
}, ...
}
How to export Yellow Pages data to Google Sheets
In order to be able to export our Yellow Pages listings to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "listings", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
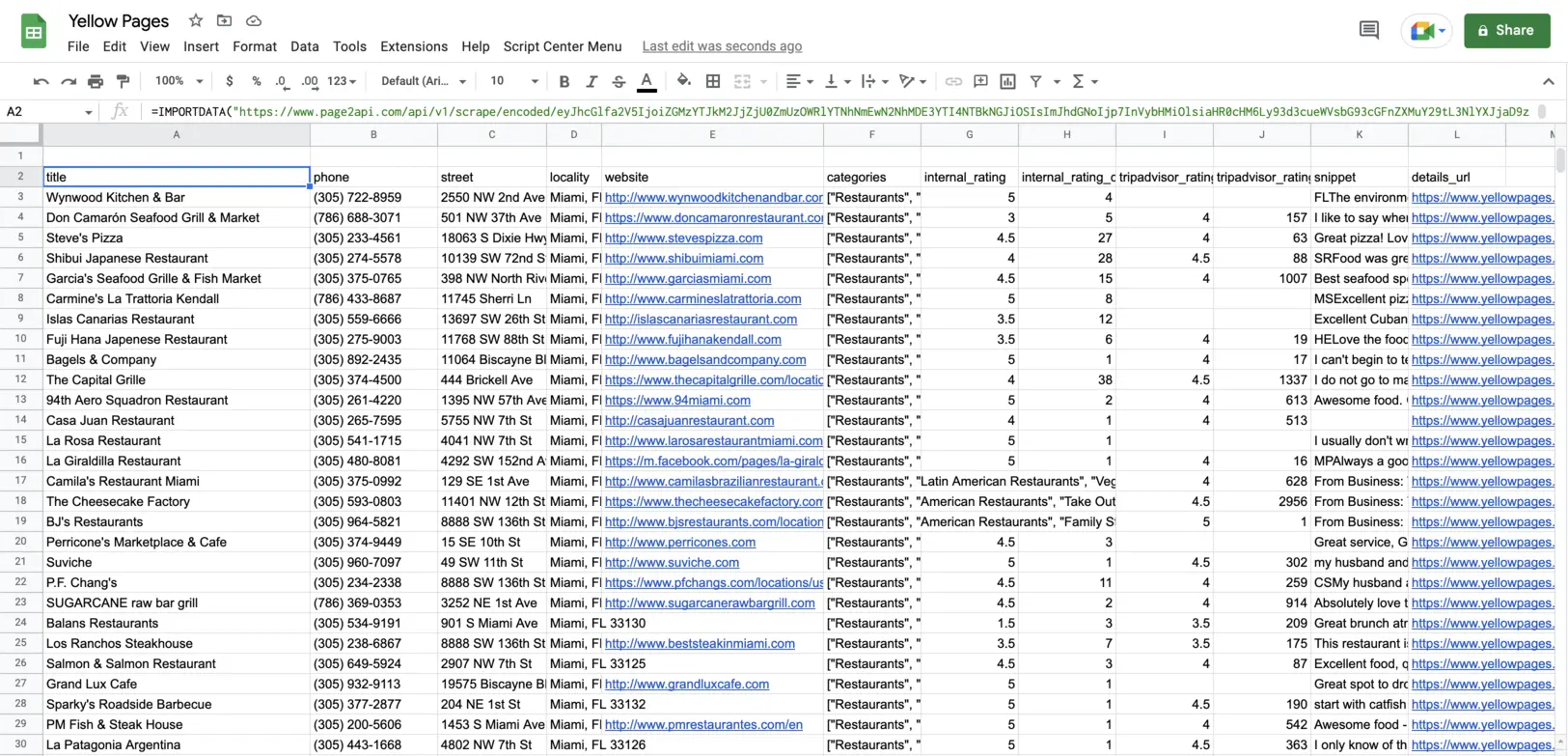
Final thoughts
Scraping Yellow Pages manually can be a bit challenging and hard to scale.
However, a Web Scraping API can easily help you overcome this hassle and scrape the data in no time.
With Page2API you can quickly get access to the data you need, and use the time you saved on more important things!
