
Introduction
Airbnb is an online marketplace that connects people who want to rent out their homes with people who are looking for accommodations in specific locales.
In this article, you will read about the easiest way to scrape Airbnb listings with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Airbnb listings into Google Sheets.
You can scrape Airbnb data, with such information as amenities, prices, descriptions, photos, URLs to perform:
- price monitoring
- trends analysis
- competitor analysis
- or simply to find the perfect vacation spot
In this article, we will learn how to:
- Scrape Airbnb listings
- Scrape Airbnb listing details
Prerequisites
To start scraping Airbnb, you will need the following things:
- A Page2API account
- A location, in which we want to search for listings, let's use for example Amsterdam, Netherlands
How to scrape Airbnb listings
First, we need to open the Airbnb search page with the desired location.
https://www.airbnb.com/s/Amsterdam--Netherlands/homes
This URL is the first parameter we need to start scraping the listings page.
The page we see must look similar to the following one:
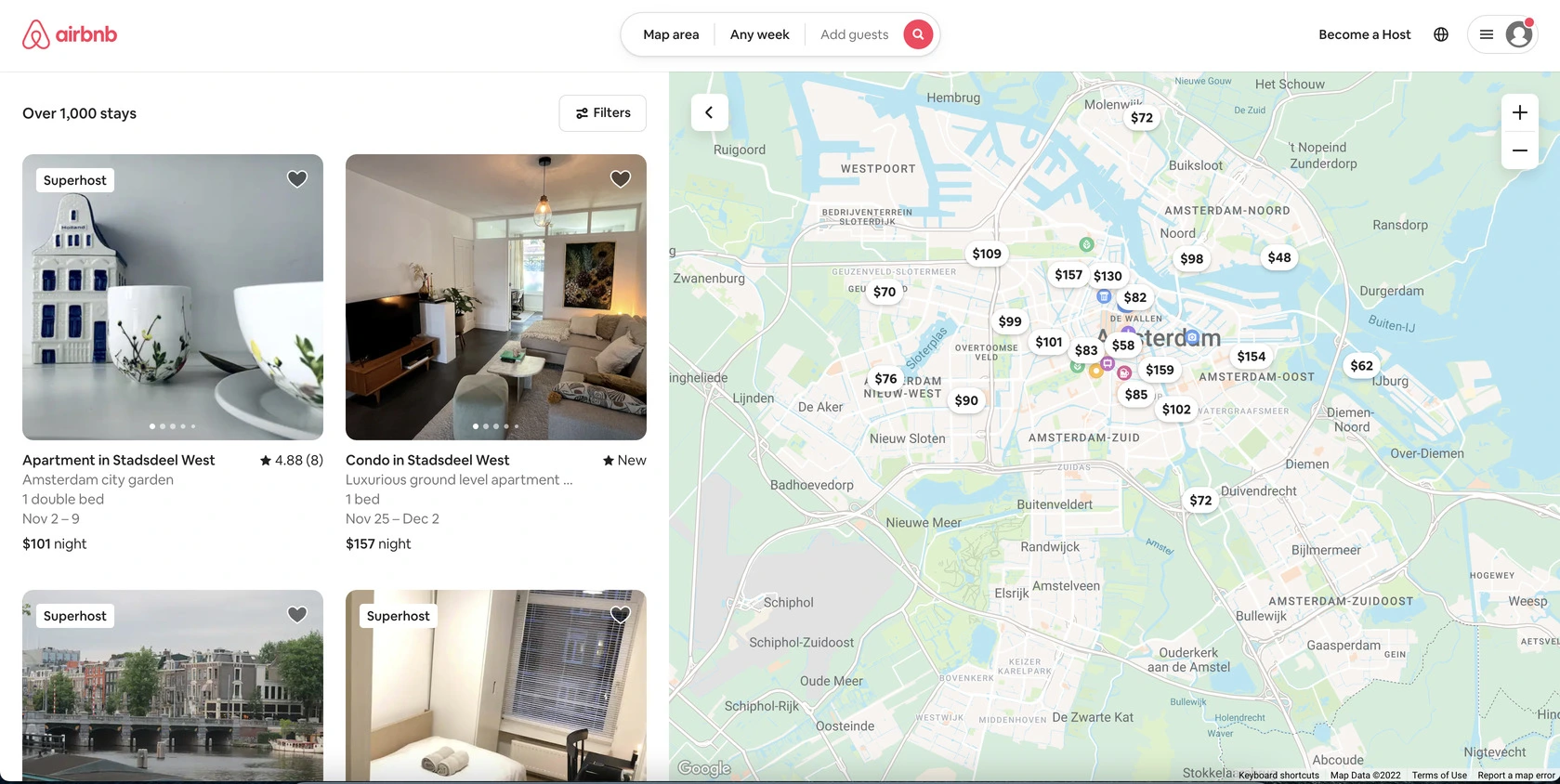
From the search page, we will scrape the following attributes:
- URL
- Title
- Name
- Beds
- Rating
- Price
Each listing container is wrapped in a div element with the following attribute: itemprop="itemListElement".
Now, let's define the selectors for each attribute.
/* Parent: */
[itemprop=itemListElement]
/* URL: */
a[target*='listing_']
/* Title: */
[id*='title']
/* Name: */
[itemprop=name]
/* Beds: */
[aria-label*='bed']
/* Rating: */
[data-testid=price-availability-row] + div > span span:nth-of-type(3)
/* Price: */
[style*='--pricing'] > div > span > div > span
Now, let's handle the pagination.
// Page 1
https://www.airbnb.com/s/Amsterdam--Netherlands/homes?pagination_search=true&items_offset=0
// Page 2
https://www.airbnb.com/s/Amsterdam--Netherlands/homes?pagination_search=true&items_offset=20
// Page 3
https://www.airbnb.com/s/Amsterdam--Netherlands/homes?pagination_search=true&items_offset=40
This looks like a great scenario to use the batch scraping approach.
Now let's build the request that will scrape all listings that the search page returned.
The following examples will show how to scrape 3 pages of listings from Airbnb.com
{
"api_key": "YOUR_PAGE2API_KEY",
"batch": {
"urls": "https://www.airbnb.com/s/Amsterdam--Netherlands/homes?pagination_search=true&items_offset=[0, 40, 20]",
"concurrency": 1,
"merge_results": true
},
"parse": {
"listings": [
{
"url": "a[target*='listing_'] >> href",
"beds": "[aria-label*='bed'] >> text",
"name": "[itemprop=name] >> content",
"price": "[style*='--pricing'] > div > span > div > span >> text",
"title": "[id*='title'] >> text",
"rating": "[data-testid=price-availability-row] + div > span span:nth-of-type(3) >> text",
"_parent": "[itemprop=itemListElement]"
}
]
},
"wait_for": "[itemprop=itemListElement]",
"real_browser": true,
"premium_proxy": "us"
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
batch: {
urls: "https://www.airbnb.com/s/Amsterdam--Netherlands/homes?pagination_search=true&items_offset=[0, 40, 20]",
concurrency: 1,
merge_results: true
},
parse: {
listings: [
{
url: "a[target*='listing_'] >> href",
beds: "[aria-label*='bed'] >> text",
name: "[itemprop=name] >> content",
price: "[style*='--pricing'] > div > span > div > span >> text",
title: "[id*='title'] >> text",
rating: "[data-testid=price-availability-row] + div > span span:nth-of-type(3) >> text",
_parent: "[itemprop=itemListElement]"
}
]
},
wait_for: "[itemprop=itemListElement]",
real_browser: true,
premium_proxy: "us"
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"listings": [
{
"url": "https://www.airbnb.com/rooms/3982031?adults=1&children=0&infants=0&check_in=2022-08-20&check_out=2022-08-27&previous_page_section_name=1000&federated_search_id=b79f5e55-f2f6-40db-baae-db124484bd1e",
"beds": "1 double bed",
"name": "Top location, quiet guesthouse, 2p",
"price": "$113",
"title": "Guesthouse in Stadsdeel Centrum",
"rating": "4.93 (147)"
},
{
"url": "https://www.airbnb.com/rooms/51760555?adults=1&children=0&infants=0&check_in=2022-11-02&check_out=2022-11-09&previous_page_section_name=1000&federated_search_id=b79f5e55-f2f6-40db-baae-db124484bd1e",
"beds": "1 double bed",
"name": "Amsterdam city garden",
"price": "$87",
"title": "Apartment in Stadsdeel West",
"rating": "4.88 (8)"
},
...
]
}, ...
}
How to scrape Airbnb listing details
From the 'Search' page, we click on any listing.
https://www.airbnb.com/rooms/3163509
The page will look like the following one:
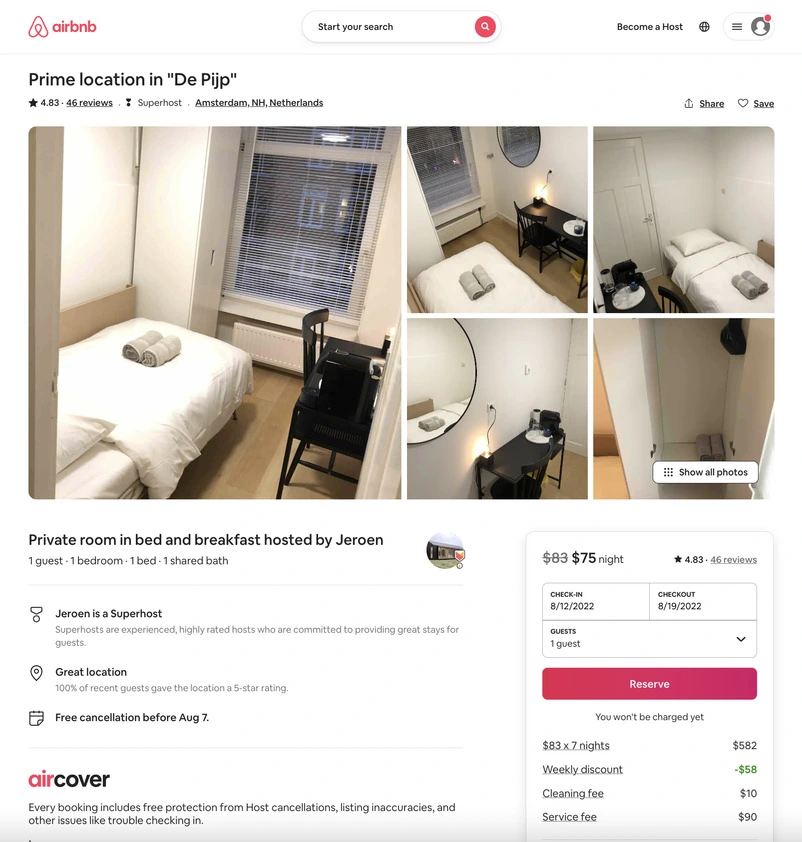
From this page, we will scrape the following attributes:
- Title
- Superhost
- Guests
- Bedrooms
- Beds
- Baths
- Reviews
- Rating
- Price
- Description
- Amenities
- Images
Let's define the selectors for each attribute.
/* Title: */
.ds-summary-row span
/* Superhost: */
//span[contains(text(),'Superhost')]
/* Guests: */
//span[contains(text(),'guests')]
/* Bedrooms: */
//span[contains(text(),'bedrooms')]
/* Beds: */
//span[contains(text(),'beds')]
/* Baths: */
//span[contains(text(),'baths')]
/* Price: */
[style*='--pricing'] > div > span > div > span
/* Images: */
picture img
/* Reviews / Rating */
// we will encode it to base64 later
var ratingObject = document.querySelector("[aria-label*='Rated']").attributes['aria-label'].nodeValue.match(/Rated (?[\d?\.]+).+ from\s(?[\d]+)/).groups;
// reviews js selector
ratingObject['reviews']
// rating js selector
ratingObject['rating']
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.airbnb.com/rooms/3163509",
"parse": {
"title": "h1 >> text",
"superhost": "//span[contains(text(),'Superhost')] >> text",
"guests": "//span[contains(text(),'guests')] >> text",
"bedrooms": "//span[contains(text(),'bedrooms')] >> text",
"beds": "//span[contains(text(),'beds')] >> text",
"baths": "//span[contains(text(),'baths')] >> text",
"reviews": "js >> ratingObject['reviews']",
"rating": "js >> ratingObject['rating']",
"price": "[style*='--pricing'] > div > span > div > span >> text",
"images": ["picture img >> data-original-uri"]
},
"scenario": [
{ "wait": 3 },
{
"execute_js": "dmFyIHJhdGluZ09iamVjdCA9IGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3IoIlthcmlhLWxhYmVsKj0nUmF0ZWQnXSIpLmF0dHJpYnV0ZXNbJ2FyaWEtbGFiZWwnXS5ub2RlVmFsdWUubWF0Y2goL1JhdGVkICg/PHJhdGluZz5bXGQ/XC5dKykuKyBmcm9tXHMoPzxyZXZpZXdzPltcZF0rKS8pLmdyb3VwczsK"
},
{ "execute": "parse" }
],
"premium_proxy": "us",
"real_browser": true
}
require 'rest_client'
require 'json'
api_url ="https://www.page2api.com/api/v1/scrape"
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.airbnb.com/rooms/3163509",
parse: {
title: "h1 >> text",
superhost: "//span[contains(text(),'Superhost')] >> text",
guests: "//span[contains(text(),'guests')] >> text",
bedrooms: "//span[contains(text(),'bedrooms')] >> text",
beds: "//span[contains(text(),'beds')] >> text",
baths: "//span[contains(text(),'baths')] >> text",
reviews: "js >> ratingObject['reviews']",
rating: "js >> ratingObject['rating']",
price: "[style*='--pricing'] > div > span > div > span >> text",
images: ["picture img >> data-original-uri"]
},
scenario: [
{ wait: 3 },
{
execute_js: "dmFyIHJhdGluZ09iamVjdCA9IGRvY3VtZW50LnF1ZXJ5U2VsZWN0b3IoIlthcmlhLWxhYmVsKj0nUmF0ZWQnXSIpLmF0dHJpYnV0ZXNbJ2FyaWEtbGFiZWwnXS5ub2RlVmFsdWUubWF0Y2goL1JhdGVkICg/PHJhdGluZz5bXGQ/XC5dKykuKyBmcm9tXHMoPzxyZXZpZXdzPltcZF0rKS8pLmdyb3VwczsK"
},
{ execute: "parse" }
],
premium_proxy: "us",
real_browser: true
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"title": "Family Houseboat in City Center",
"superhost": "Superhost",
"guests": "2 guests",
"bedrooms": "2 bedrooms",
"beds": "3 beds",
"baths": "1.5 baths",
"reviews": "42",
"rating": "4.95",
"price": "$138",
"images": [
"https://a0.muscache.com/pictures/40535051/7c49b7a2_original.jpg",
"https://a0.muscache.com/pictures/40309400/2ed629ab_original.jpg",
"https://a0.muscache.com/pictures/40309387/abf52119_original.jpg",
"https://a0.muscache.com/pictures/miso/Hosting-3163509/original/871a0673-e4ea-4afa-a90d-c3fa946ab491.jpeg",
"https://a0.muscache.com/pictures/miso/Hosting-3163509/original/d2fb3e01-a9e4-4374-b722-9d6952356734.jpeg"
]
}
}
How to export Airbnb listings to Google Sheets
In order to be able to export our Airbnb listings to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "listings", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
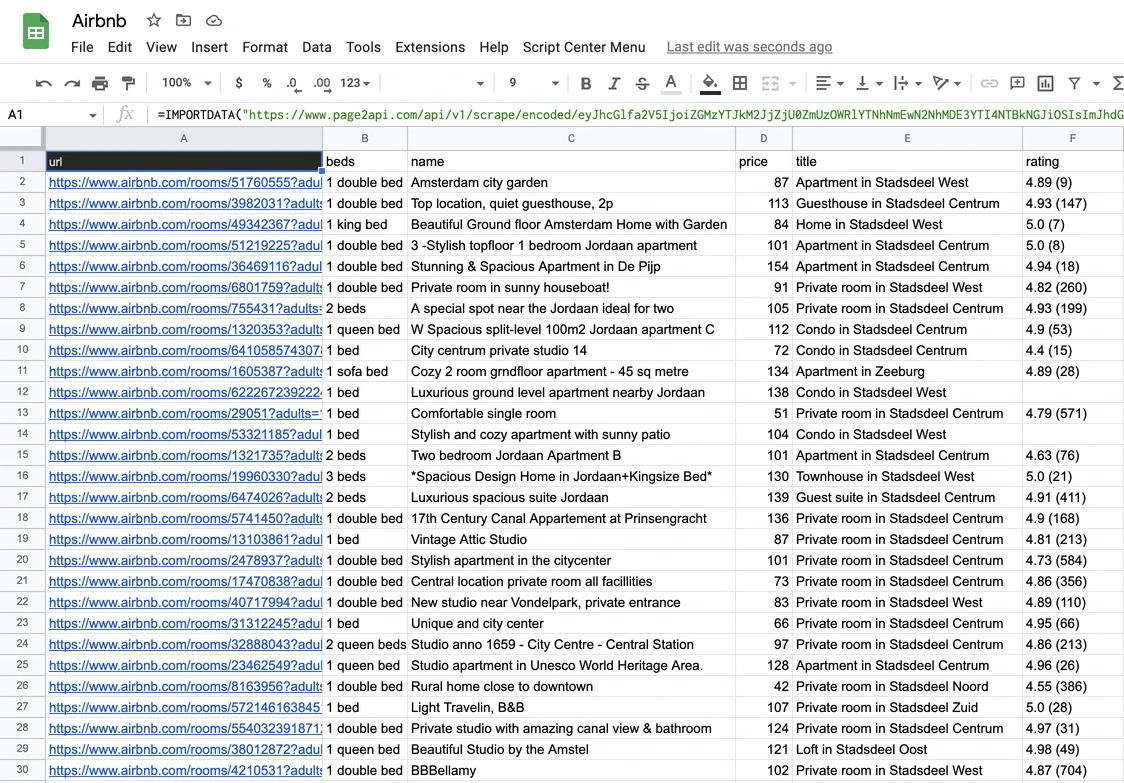
Final thoughts
Collecting Airbnb data manually can be a bit overwhelming and hard to scale.
However, a Web Scraping API can easily help you overcome this challenge and scrape the data in no time.
With Page2API you can quickly get access to the data you need, and use the time you saved on more important things!
