
Introduction
Instagram is a free social networking service built around sharing photos and videos with your followers.
In this article, you will read about the easiest way to web scrape Instagram data with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Instagram posts into Google Sheets.
In this article, we will learn how to:
Prerequisites
To start scraping Instagram, you will need the following things:
- A Page2API account
- A Instagram profile you want to scrape, let's use for example NASA
How to scrape Instagram Account Data
The first thing you need is to open the profile page we are interested in.
https://www.instagram.com/nasa/
The page will look like the following one:
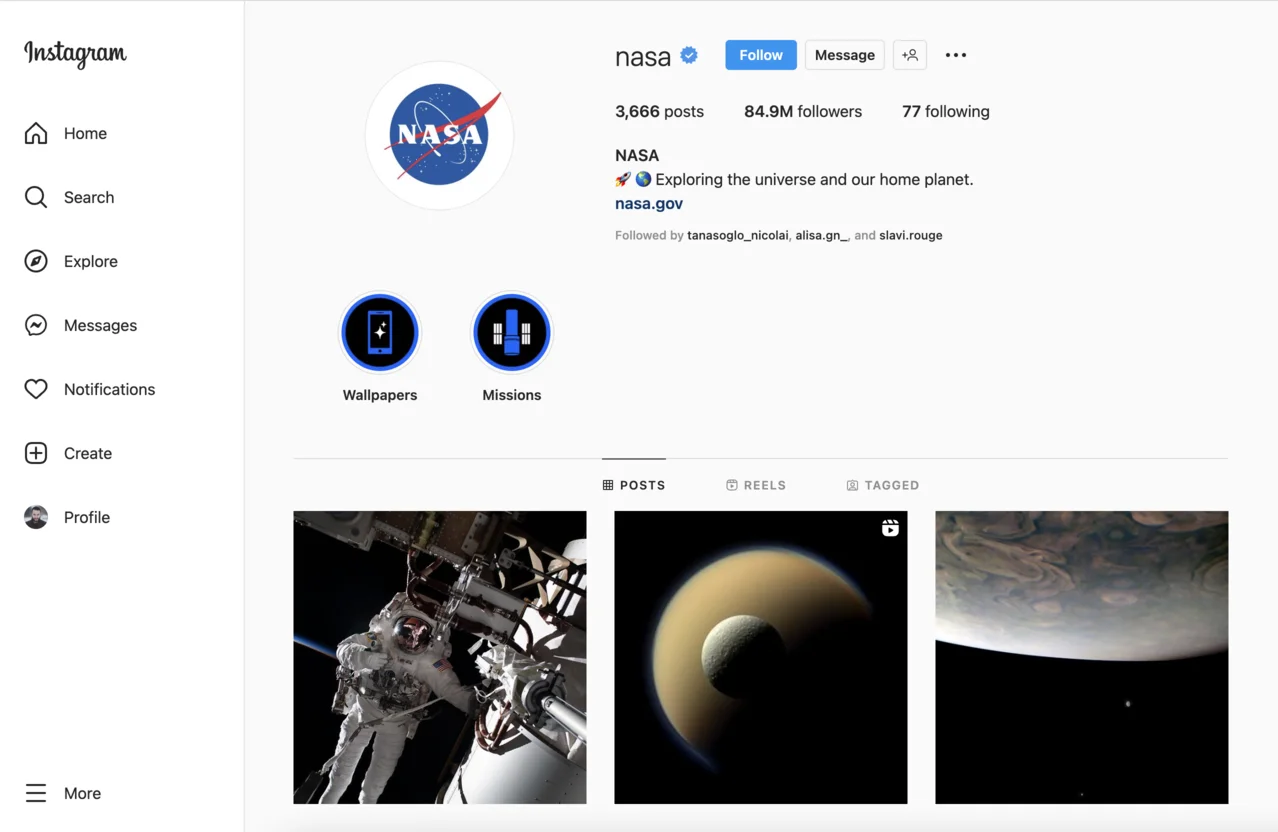
From this page, we will scrape the following attributes:
Instagram Account data
- Name
- Followers
- Following
- Posts
- Title
- Bio
- Bio URL
Latest posts
- Title
- Image
- URL
Let's define the selectors for each attribute.
Instagram Account data selectors
/* Name: */
header h2
/* Posts: */
header ul li:nth-of-type(1) div span
/* Followers: */
header ul li:nth-of-type(2) div span
/* Following: */
header ul li:nth-of-type(3) div span
/* Title: */
header ul + div span
/* Bio: */
header ul + div div
/* Bio URL: */
header ul + div a
Latest posts selectors
/* Parent: */
article a[role=link]
/* Title: */
img
/* Image: */
img
/* URL: */
article a[role=link]
Before starting to scrape we must ensure that the cookies modal is closed
for (const a of document.querySelectorAll('div[role=dialog] button')) {
if (a.textContent.includes('essential cookies')) {
a.click()
}
}
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.instagram.com/nasa/",
"parse": {
"name": "header h2 >> text",
"posts": "header ul li:nth-of-type(1) div span >> text",
"followers": "header ul li:nth-of-type(2) div span >> text",
"following": "header ul li:nth-of-type(3) div span >> text",
"title": "header section > div:nth-of-type(3) span >> text",
"bio": "header section > div:nth-of-type(3) > div:nth-of-type(3) >> text",
"link": "header section > div:nth-of-type(3) > button > div >> text",
"latest_posts": [
{
"_parent": "article a[role=link]",
"image": "img >> src",
"link": "_parent >> href",
"title": "img >> alt"
}
]
},
"premium_proxy": "us",
"real_browser": true,
"scenario": [
{ "execute_js": "for (const a of document.querySelectorAll('div[role=dialog] button')) { if (a.textContent.includes('essential cookies')) { a.click() }}" },
{ "wait_for": "header h2" },
{ "execute": "parse" }
]
}
require 'rest_client'
require 'json'
api_url ="https://www.page2api.com/api/v1/scrape"
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.instagram.com/nasa/",
parse: {
name: "header h2 >> text",
posts: "header ul li:nth-of-type(1) div span >> text",
followers: "header ul li:nth-of-type(2) div span >> text",
following: "header ul li:nth-of-type(3) div span >> text",
title: "header section > div:nth-of-type(3) span >> text",
bio: "header section > div:nth-of-type(3) > div:nth-of-type(3) >> text",
link: "header section > div:nth-of-type(3) > button > div >> text",
latest_posts: [
{
_parent: "article a[role=link]",
image: "img >> src",
link: "_parent >> href",
title: "img >> alt"
}
]
},
premium_proxy: "us",
real_browser: true,
scenario: [
{ execute_js: "for (const a of document.querySelectorAll('div[role=dialog] button')) { if (a.textContent.includes('essential cookies')) { a.click() }}" },
{ wait_for: "header h2" },
{ execute: "parse" }
]
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
print(result)
{
"result": {
"name": "nasa",
"posts": "3,666",
"followers": "84.9M",
"following": "77",
"title": "NASA",
"bio": "🚀 🌎 Exploring the universe and our home planet.",
"bio_url": "nasa.gov",
"latest_posts": [
{
"image": "https://scontent-bos5-1.cdninstagram.com/v/t51.2885-15/316365871_1180016569589333_2961860102150934780_n.jpg...",
"url": "https://www.instagram.com/p/ClNLBXytoyy/",
"title": "The last rays of an orbital sunset @Astro_FrankRubio is pictured during a Nov. 15, 2022, spacewalk outside @ISS. ..."
},
{
"image": "https://scontent-bos5-1.cdninstagram.com/v/t51.2885-15/315952827_1353287375409485_6061058986499004221_n.jpg...",
"url": "https://www.instagram.com/p/ClJnD6hDbJQ/",
"title": "Where do moons come from? We asked a NASA expert. From cataclysmic impacts to gravitational capture, NASA ..."
},
{
"image": "https://scontent-bos5-1.cdninstagram.com/v/t51.2885-15/315951420_817027662731641_7325911233050593105_n.jpg...",
"url": "https://www.instagram.com/p/ClHL-M-L1g_/",
"title": "Good things come in threes. As our Juno spacecraft completed its 38th close flyby of Jupiter on November 29, 2021, ..."
},
...
]
} ...
}
How to scrape Instagram Posts by Hashtag
First, we need to open the Instagram explore page with the desired hashtag.
https://www.instagram.com/explore/tags/nasa/
The page we see must look similar to the following one:
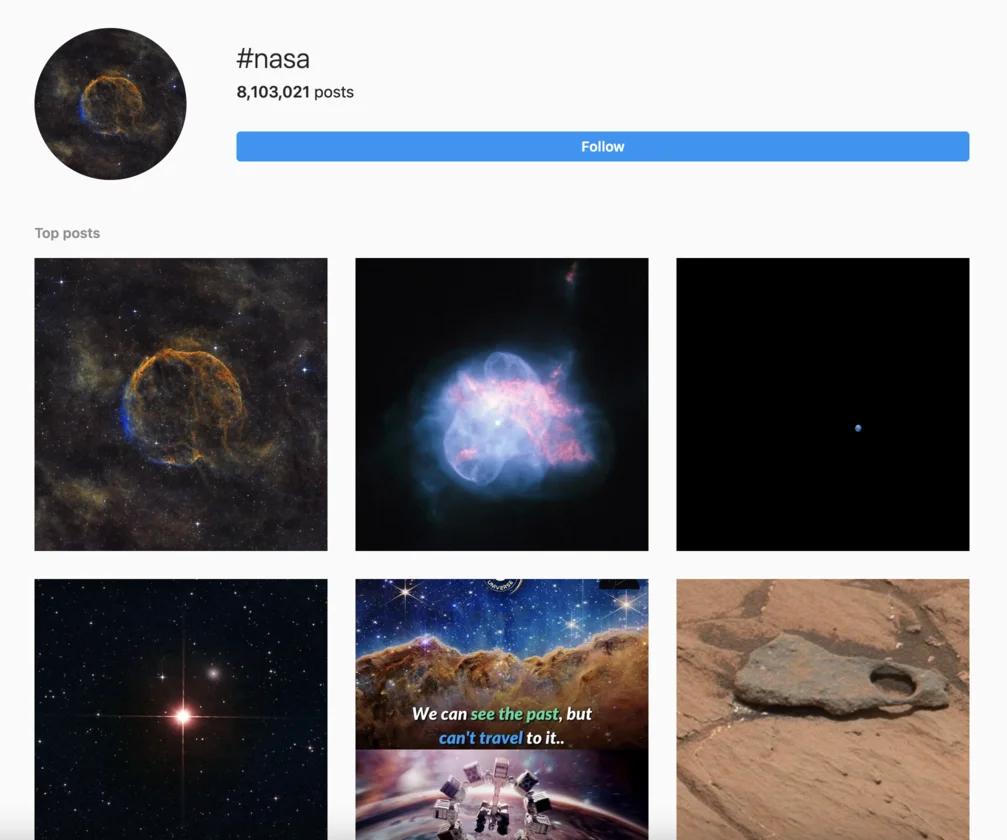
From this page, we will scrape the following attributes for each post:
- Title
- Image
- URL
Now, let's define the selectors for each attribute.
/* Parent: */
article a[role=link]
/* Title: */
img
/* Image: */
img
/* URL: */
article a[role=link]
Now, let's handle the pagination.
document.querySelectorAll('article a[role=link] img').forEach(e => e.scrollIntoView({behavior: 'smooth'}))
And let's not forget to close the Login modal:
document.querySelector('#scrollview + div')?.remove()
Now let's build the request that will scrape all posts that the Instagram explore page returned.
The following examples will show how to scrape 2 pages of posts from Instagram's explore page.
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.instagram.com/explore/tags/nasa/",
"parse": {
"posts": [
{
"_parent": "article a[role=link]",
"image": "img >> src",
"url": "_parent >> href",
"title": "img >> alt"
}
]
},
"premium_proxy": "us",
"real_browser": true,
"scenario": [
{ "wait_for": "article a[role=link]" },
{
"loop": [
{ "execute_js": "document.querySelector('#scrollview + div')?.remove();" },
{ "wait": 1 },
{ "execute_js": "document.querySelectorAll('article a[role=link] img').forEach(e => e.scrollIntoView({behavior: 'smooth'}))" }
],
"iterations": 2
},
{ "execute": "parse" }
]
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
url: "https://www.instagram.com/explore/tags/nasa/",
parse: {
posts: [
{
_parent: "article a[role=link]",
image: "img >> src",
url: "_parent >> href",
title: "img >> alt"
}
]
},
premium_proxy: "us",
real_browser: true,
scenario: [
{ wait_for: "article a[role=link]" },
{
loop: [
{ execute_js: "document.querySelector('#scrollview + div')?.remove();" },
{ execute_js: "document.querySelectorAll('article a[role=link] img').forEach(e => e.scrollIntoView({behavior: 'smooth'}))" },
{ wait: 1 }
],
iterations: 2
},
{
execute: "parse"
}
]
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"posts": [
{
"image": "https://scontent-atl3-1.cdninstagram.com/v/t51.2885-15/316458796_1178373929701303_4921666824295792341_n.webp...",
"url": "https://www.instagram.com/p/ClNbXaVjDKK/",
"title": "#mars_patrol #telescope #spacestation #spacecraft#spacefacts #spacex #spaceexploration#spaceexplorer #deepspace ..."
},
{
"image": "https://scontent-atl3-1.cdninstagram.com/v/t51.2885-15/316028358_170197002356991_5274268877404243353_n.jpg...",
"url": "https://www.instagram.com/p/ClLr9-euv6_/",
"title": "Share this with a friend you like go follow @_finitespace_ go follow @_finitespace_ credit: @astro.lust .."
},
{
"image": "https://scontent-atl3-1.cdninstagram.com/v/t51.2885-15/316105918_508048054703186_715273589769818265_n.webp...",
"url": "https://www.instagram.com/p/ClMntrbpNI8/",
"title": "An illustration of a beautiful black hole. -Uma ilustração de um belo buraco negro. . . . . @nasa . . "
},
{
"image": "https://scontent-atl3-1.cdninstagram.com/v/t51.2885-15/316597716_108405495342768_8303989679343993556_n.webp...",
"url": "https://www.instagram.com/p/ClMquhaDKqf/",
"title": "There it is! The Moon! . \"We're approaching the Moon ahead of our powered flyby maneuver during ..."
}, ...
]
}, ...
}
How to export Instagram posts to Google Sheets
In order to be able to export our posts to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "posts", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
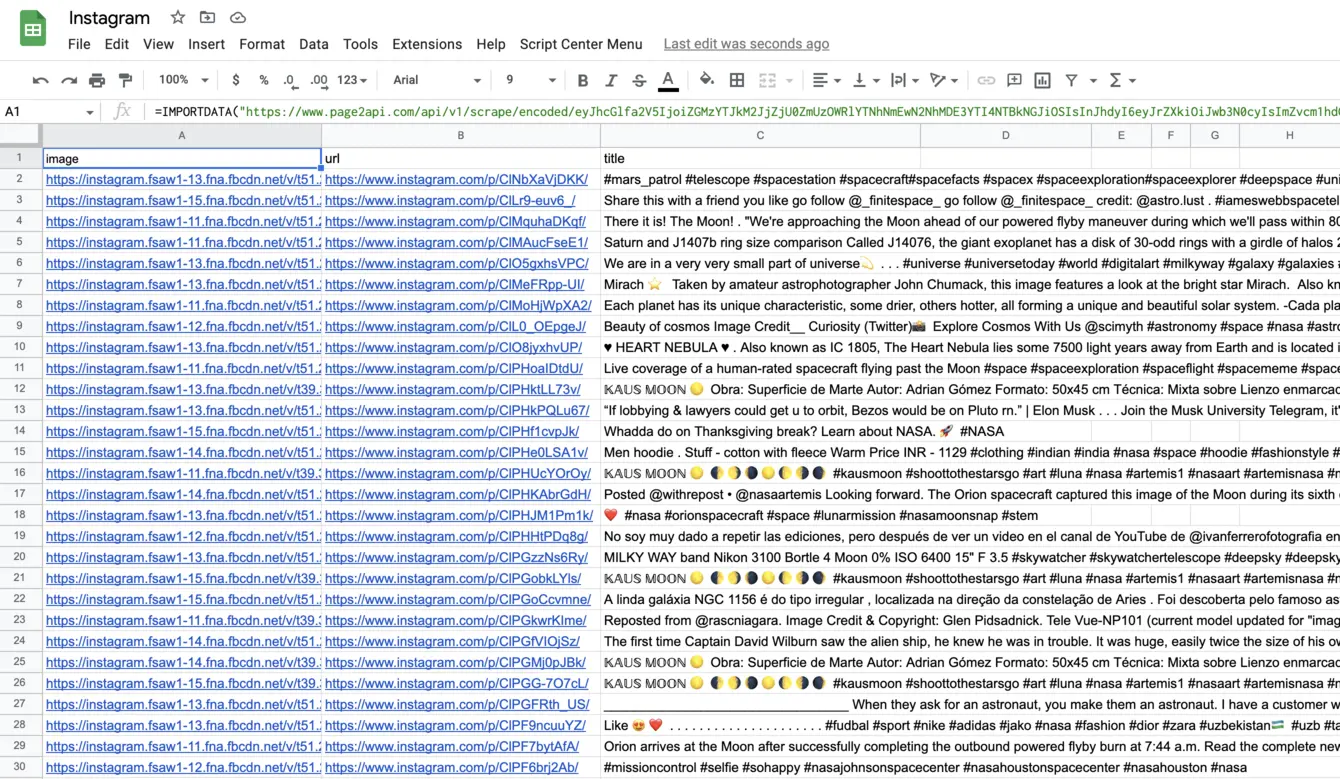
Final thoughts
Collecting the data from Instagram manually can be a bit overwhelming and hard to scale.
However, a Web Scraping API can easily help you overcome this challenge and perform Instagram scraping in no time.
With Page2API you can quickly get access to the data you need, and use the time you saved on more important things!
And by by the way, if you are interested in a detailed article on how to build an iPhone shortcut that will help you download Instagram videos with Page2API, here is the link:
https://www.page2api.com/blog/download-instagram-video-iphone/
