
Introduction
Reddit.com is a social news website and forum where content is socially curated and promoted by site members through voting.
In this article, you will read about the easiest way to scrape Reddit posts and comments with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Reddit posts into Google Sheets.
To scrape Reddit, we will use Page2API - a powerful and delightful API that will help you scrape the web like a PRO.
Prerequisites
To start scraping Reddit posts, we will need the following things:
- A Page2API account
-
The link to a subreddit that we are about to scrape.
To make the scraping process easier - we will use the old Reddit UI since it has a simpler HTML structure.
In this article, we will scrape the BMW subreddit.
How to scrape Reddit Posts
https://old.reddit.com/r/BMW/
The URL is the first parameter we need to perform the scraping.
The page that you see must look like the following one:
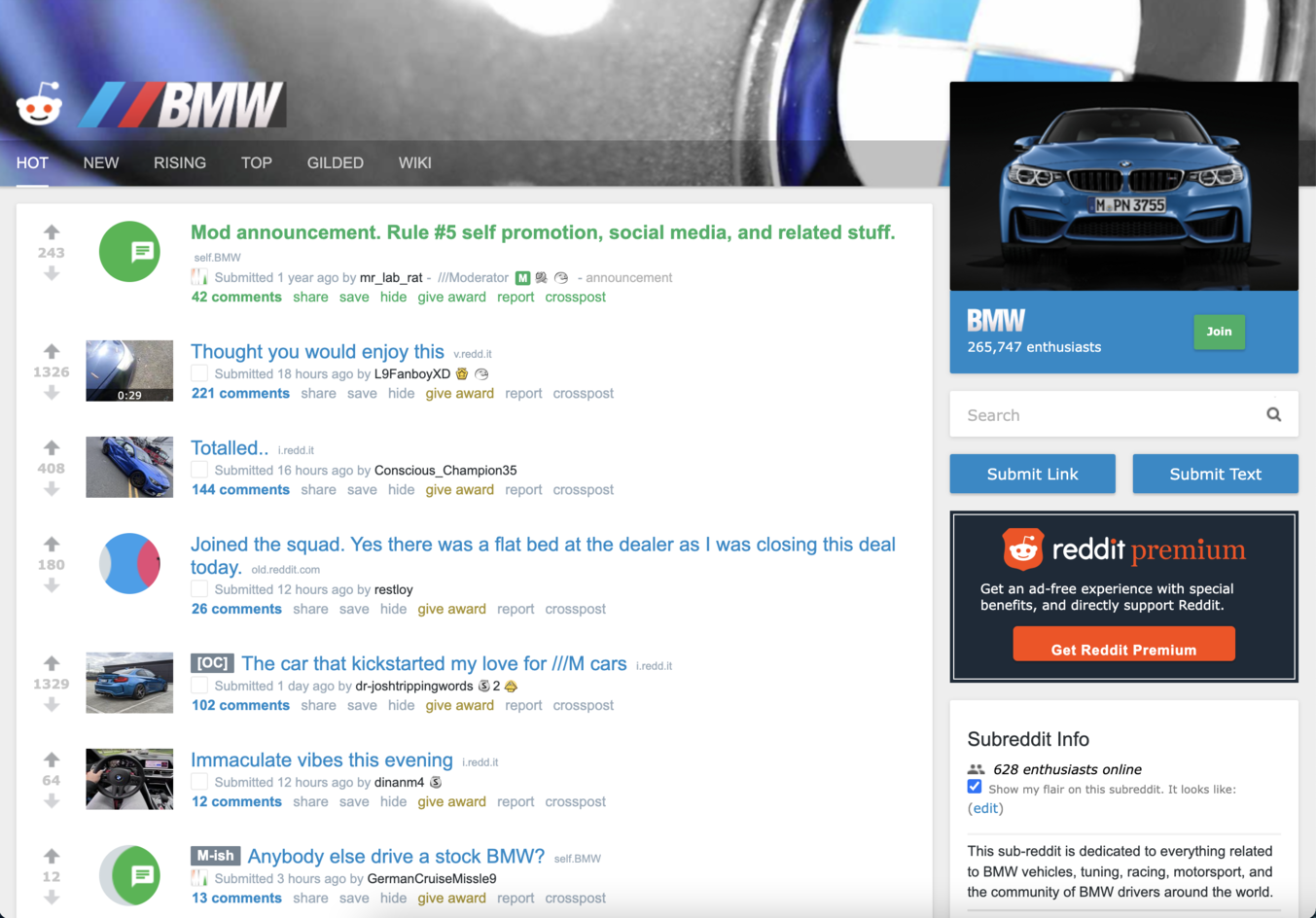
If you inspect the page HTML, you will find out that a single result is wrapped into an element that looks like the following:
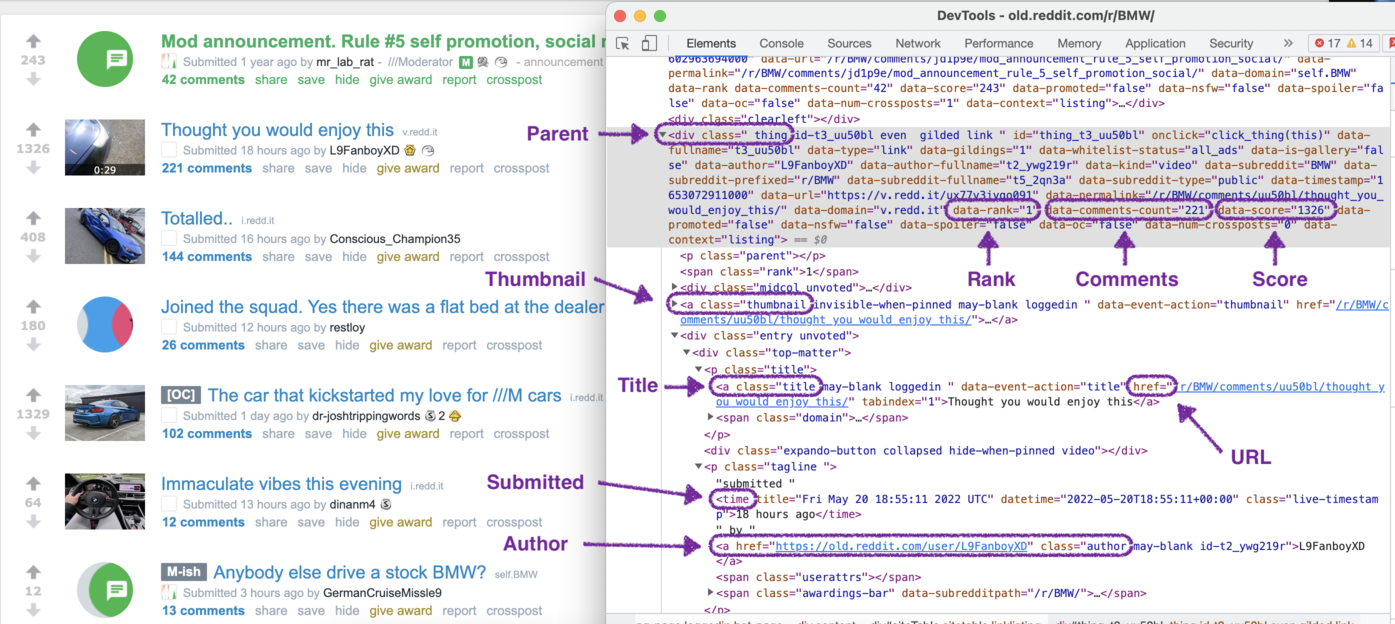 From this page, we will scrape the following attributes from each Reddit post:
From this page, we will scrape the following attributes from each Reddit post: - Title
- URL
- Thumbnail
- Submitted
- Author
- Author URL
- Comments
- Rank
- Score
Now, let's define the selectors for each attribute.
/* Parent: */
.thing[data-promoted=false]
/* Title */
a.title
/* URL */
a.title
/* Thumbnail */
a.thumbnail img
/* Submitted */
time
/* Author */
a.author
/* Author URL */
a.author
/* Comments */
(parent div, attribute: data-comments-count)
/* Rank */
(parent div, attribute: data-rank
/* Score */
(parent div, attribute: data-score
Now, let's handle the pagination.
We will iterate through the Reddit pages by clicking on the Next page button.
To go to the next page, we must click on the next page link if it's present on the page:
document.querySelector('.next-button a').click()
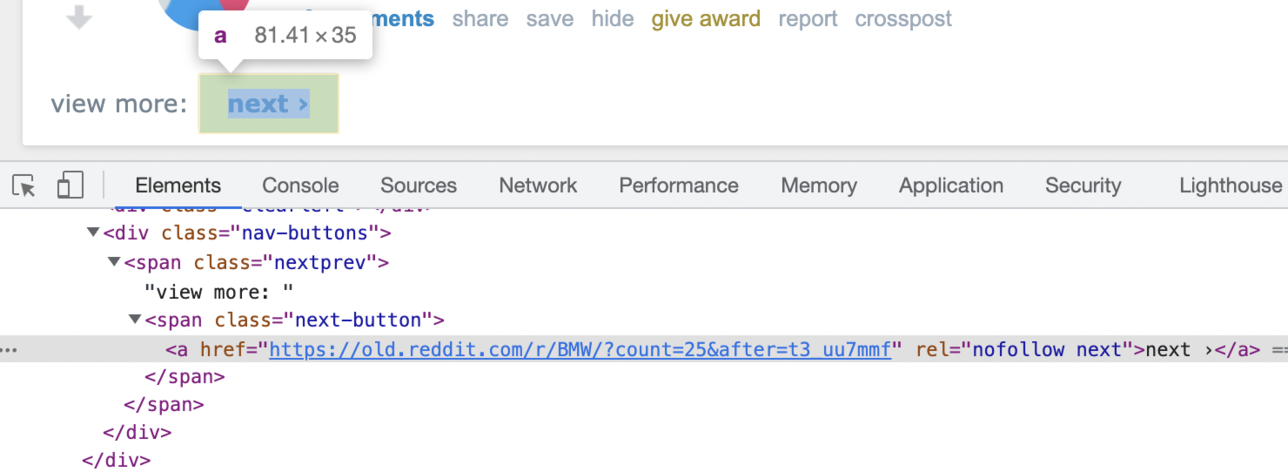
The scraping will continue while the Next link is present on the page, and stop if it disappears.
The stop condition for the scraper will be the following javascript snippet:
document.querySelector('.next-button a') === null
Let's build the request that will scrape the needed pages from this subreddit.
The following examples will show how to scrape 3 pages of posts from Reddit.com
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://old.reddit.com/r/BMW/",
"merge_loops": true,
"real_browser": true,
"javascript": false,
"scenario": [
{
"loop": [
{ "wait_for": ".thing" },
{ "execute": "parse" },
{ "click": ".next-button a" }
],
"stop_condition": "document.querySelector('.next-button a') === null",
"iterations": 3
}
],
"parse": {
"posts": [
{
"_parent": ".thing[data-promoted=false]",
"title": "a.title >> text",
"url": "a.title >> href",
"thumbnail": "a.thumbnail img >> src",
"submitted": "time >> datetime",
"author": "a.author >> text",
"author_url": "a.author >> href",
"comments": "_parent >> data-comments-count",
"rank": "_parent >> data-rank",
"score": "_parent >> data-score"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
# The following example will show how to scrape 5 pages of posts from Reddit.com
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://old.reddit.com/r/BMW/",
merge_loops: true,
real_browser: true,
javascript: false,
scenario: [
{
loop: [
{ wait_for: ".thing" },
{ execute: "parse" },
{ click: ".next-button a" }
],
stop_condition: "document.querySelector('.next-button a') === null",
iterations: 3
}
],
parse: {
posts: [
{
_parent: ".thing[data-promoted=false]",
title: "a.title >> text",
url: "a.title >> href",
thumbnail: "a.thumbnail img >> src",
submitted: "time >> datetime",
author: "a.author >> text",
author_url: "a.author >> href",
comments: "_parent >> data-comments-count",
rank: "_parent >> data-rank",
score: "_parent >> data-score"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"posts": [
{
"title": "Thought you would enjoy this",
"url": "https://old.reddit.com/r/BMW/comments/uu50bl/thought_you_would_enjoy_this/",
"thumbnail": "https://b.thumbs.redditmedia.com/1OMVuKzvOeVi6IkOMc1K94HzPOLs3InozhCPlxU8K7E.jpg",
"submitted": "2022-05-20T18:55:11+00:00",
"author": "L9FanboyXD",
"author_url": "https://old.reddit.com/user/L9FanboyXD",
"comments": "206",
"rank": "1",
"score": "1234"
},
{
"title": "Totalled..",
"url": "https://old.reddit.com/r/BMW/comments/uu7yih/totalled/",
"thumbnail": "https://b.thumbs.redditmedia.com/QQ7_MbJqhB5t4QfKJjbTFU4sEK0Cd9Cy5uFCSzzeLzM.jpg",
"submitted": "2022-05-20T21:16:40+00:00",
"author": "Conscious_Champion35",
"author_url": "https://old.reddit.com/user/Conscious_Champion35",
"comments": "130",
"rank": "2",
"score": "375"
},
{
"title": "Joined the squad. Yes there was a flat bed at the dealer as I was closing this deal today.",
"url": "https://www.reddit.com/gallery/uucgb5",
"thumbnail": "https://b.thumbs.redditmedia.com/g8vAVq0N59R0a-IX1mBtM1YEy2gouhhGTTS7m4Nr8us.jpg",
"submitted": "2022-05-21T01:16:08+00:00",
"author": "restloy",
"author_url": "https://old.reddit.com/user/restloy",
"comments": "22",
"rank": "3",
"score": "157"
}, ...
]
}, ...
}
How to scrape Reddit Comments
We need to open any post URL from the previous step.
https://old.reddit.com/r/BMW/comments/uu50bl/thought_you_would_enjoy_this/
This URL is the first parameter we need to scrape the Reddit post data and comments.
The comments section that you see must look like the following one:
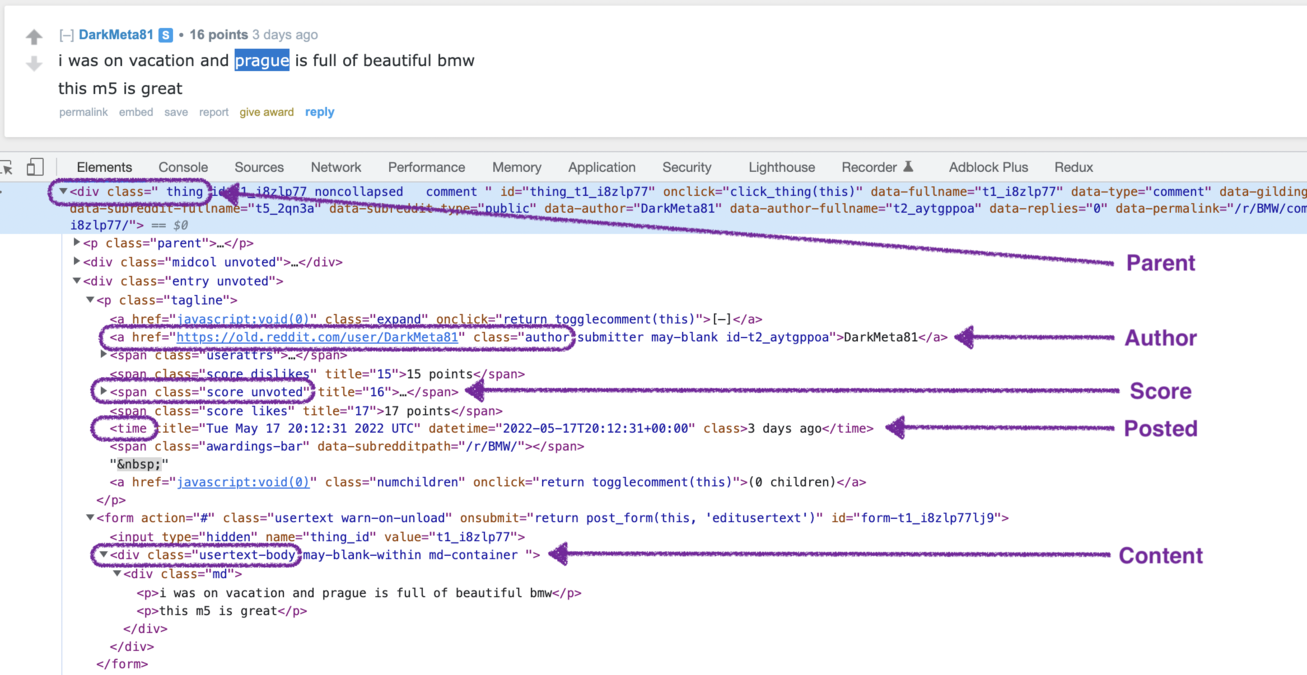 From this page, we will scrape the following attributes:
From this page, we will scrape the following attributes: Post data:
- Title
- Image
Comments data:
- Author
- Author URL
- Posted
- Score
- ID
- Content
Now, let's define the selectors for each attribute.
Post data
/* Title */
a.title
/* Image */
.media-preview-content img.preview
Comments data:
/* Parent */
.entry
/* Author */
a.author
/* Author URL */
a.author
/* Posted */
time
/* Score */
.score.unvoted
/* ID */
input[name=thing_id]
/* Content */
.usertext-body
It's time to prepare the request that will scrape the data from a Reddit post page.
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://old.reddit.com/r/BMW/comments/urv3mr/i_saw_it_in_prague_the_red_is_much_prettier_in/",
"parse": {
"title": "a.title >> text",
"image": ".media-preview-content img.preview >> src",
"comments": [
{
"_parent": ".entry",
"author": "a.author >> text",
"author_url": "a.author >> href",
"posted": "time >> datetime",
"score": ".score.unvoted >> text",
"id": "input[name=thing_id] >> value",
"content": ".usertext-body >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://old.reddit.com/r/BMW/comments/urv3mr/i_saw_it_in_prague_the_red_is_much_prettier_in/",
parse: {
title: "a.title >> text",
image: ".media-preview-content img.preview >> src",
comments: [
{
_parent: ".entry",
author: "a.author >> text",
author_url: "a.author >> href",
posted: "time >> datetime",
score: ".score.unvoted >> text",
id: "input[name=thing_id] >> value",
content: ".usertext-body >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"title": "I saw it in prague. the red is much prettier in real life",
"image": "https://preview.redd.it/91x8qz36f3091.jpg?width=1023&auto=png&s=9c0aced50d6743989f053cf9cc78c896f928d8a7",
"comments": [
{
"author": "DarkMeta81",
"author_url": "https://old.reddit.com/user/DarkMeta81",
"posted": "2022-05-17T20:12:31+00:00",
"score": "15 points",
"id": "t1_i8zlp77",
"content": "i was on vacation and prague is full of beautiful bmw this m5 is great"
},
{
"author": "Id-atl",
"author_url": "https://old.reddit.com/user/Id-atl",
"posted": "2022-05-18T01:06:15+00:00",
"score": "5 points",
"id": "t1_i90on16",
"content": "Wow imagine being in Prague ripping this around!"
}, ...
]
}, ...
}
How to export Reddit posts to Google Sheets
To export our Reddit posts to a Google Spreadsheet, we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "posts", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
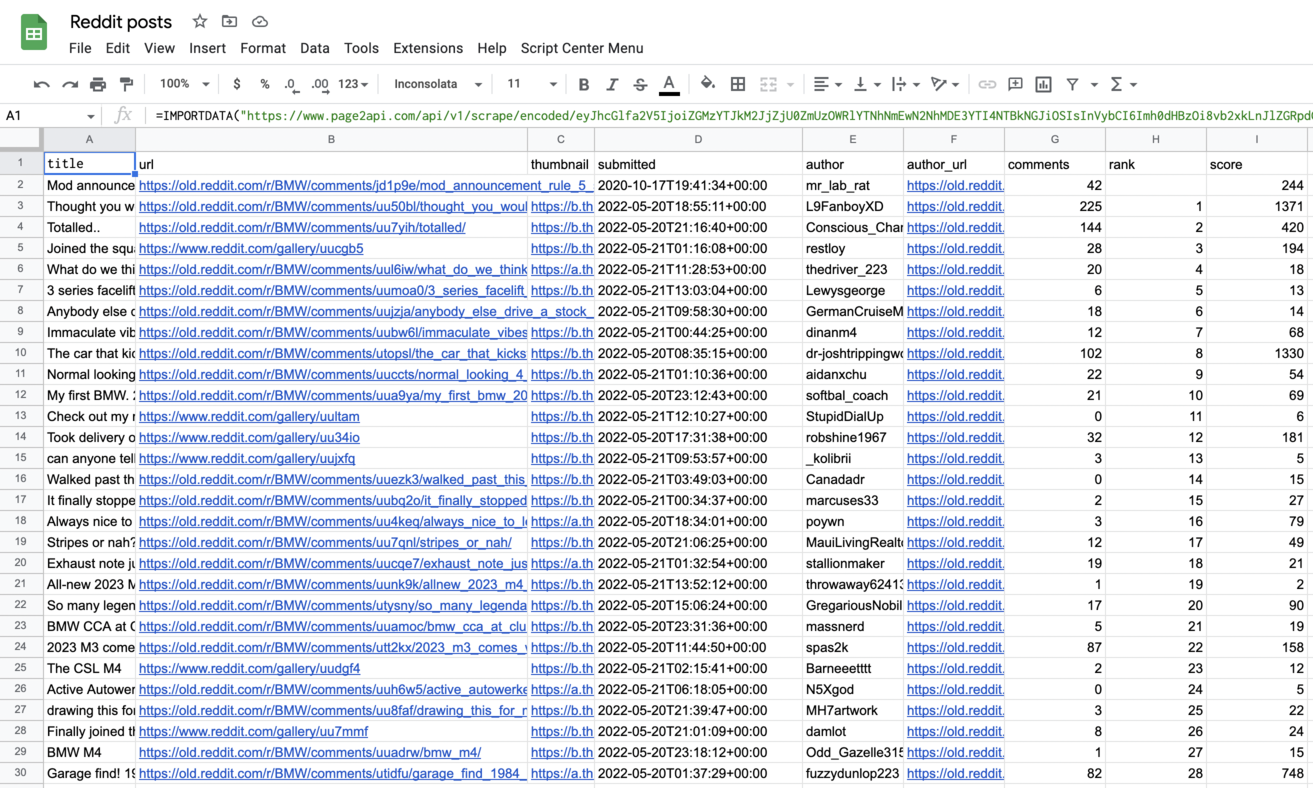
Conclusion
That's it!
In this article, you've learned how to scrape the data from Reddit.com with Page2API - a Web Scraping API that handles all the hassle, and lets you get the data you need with ease.
