
Introduction
Yelp is a popular online directory for discovering local businesses ranging from bars, restaurants, and cafes to hairdressers, spas, and gas stations.
Why do we may need to scrape Yelp?
Collecting data from Yelp will help us to perform:
- competitor analysis
- sentiment analysis
- lead generation
- price monitoring
To scrape Yelp data, we will use Page2API - a powerful and delightful API that makes web scraping easy and fun.
In this article, we will learn how to:
- Scrape Yelp Business Information
- Scrape Yelp Reviews
Prerequisites
To start scraping Yelp, we will need the following things:
- A Page2API account
-
A category of businesses in a specific location that we are about to scrape.
In our case, we will search for Restaurants in Redwood City, CA, and then pick a restaurant and scrape its reviews.
How to scrape Yelp business information
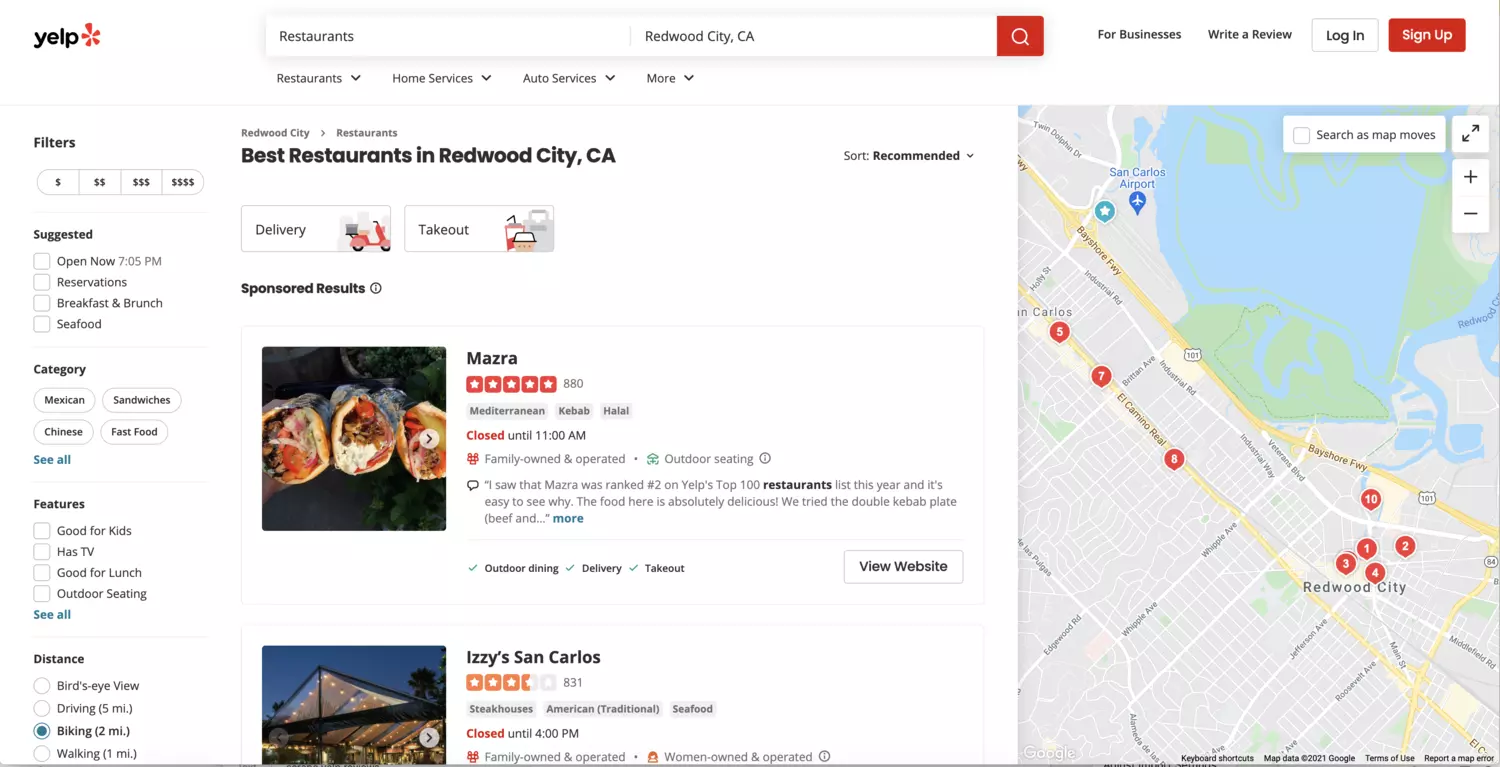
First what we need is to open yelp.com and type 'Restaurants' into the search input from the Yelp search page and pick the location we need.
https://www.yelp.com/search?find_desc=Restaurants&find_loc=Redwood+City%2C+CA
The URL is the first parameter we need to perform the scraping.
The page that you see must look like the following one:
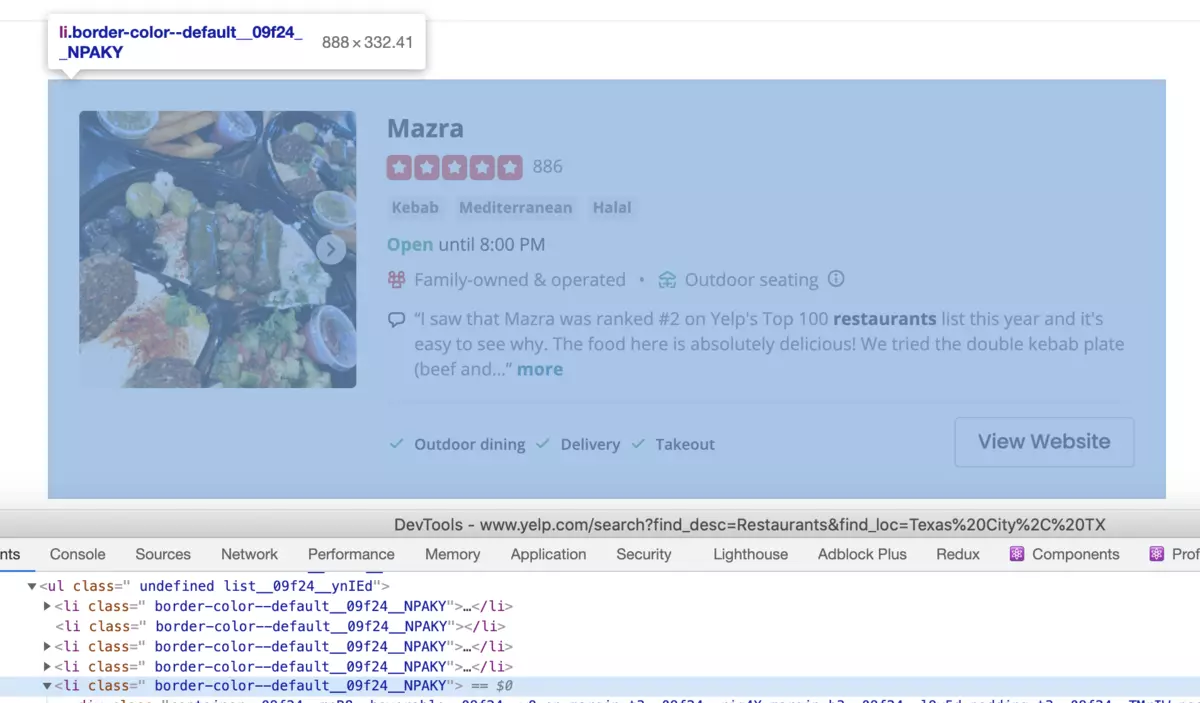
If you inspect the page HTML, you will find out that a single result is wrapped into an element that looks like the following:
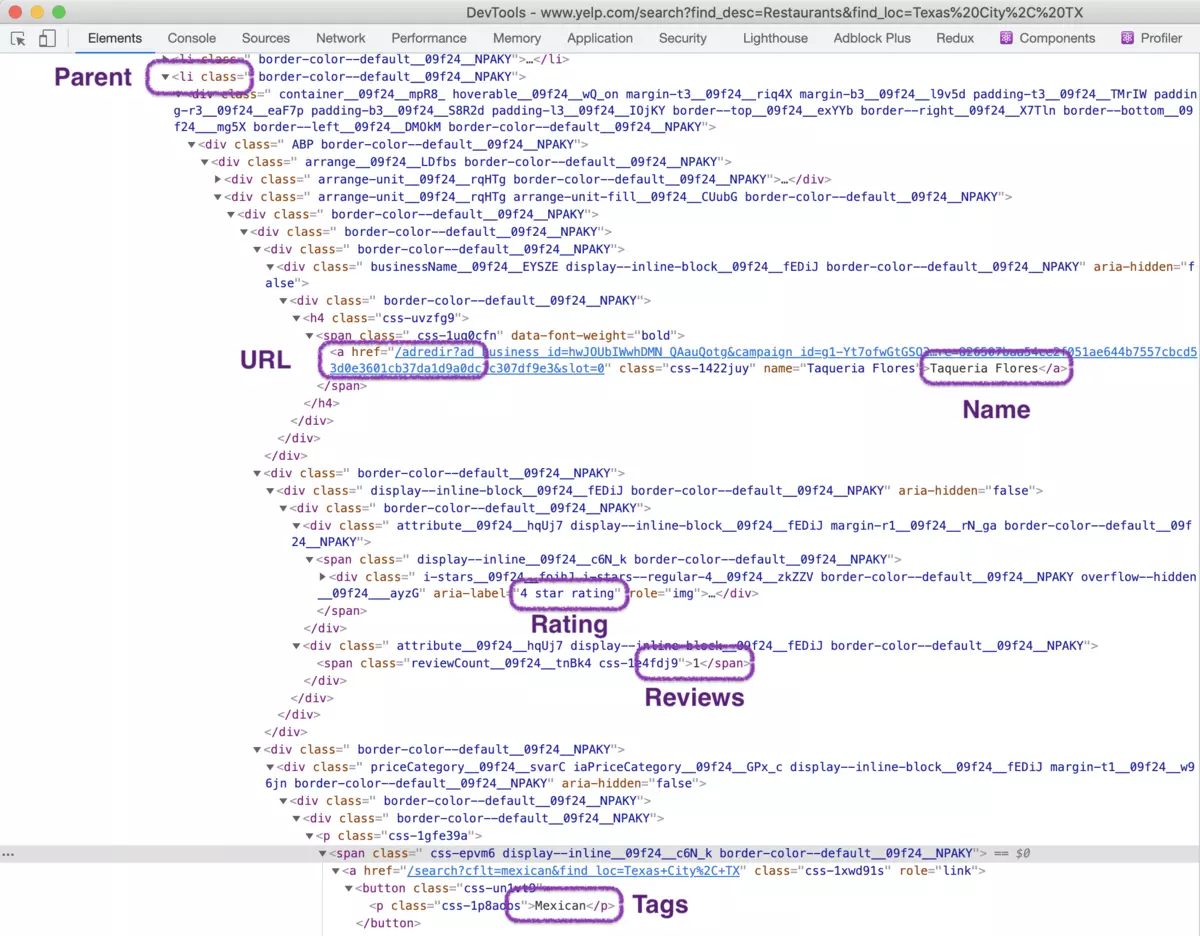
The HTML for a single result element will look like this:
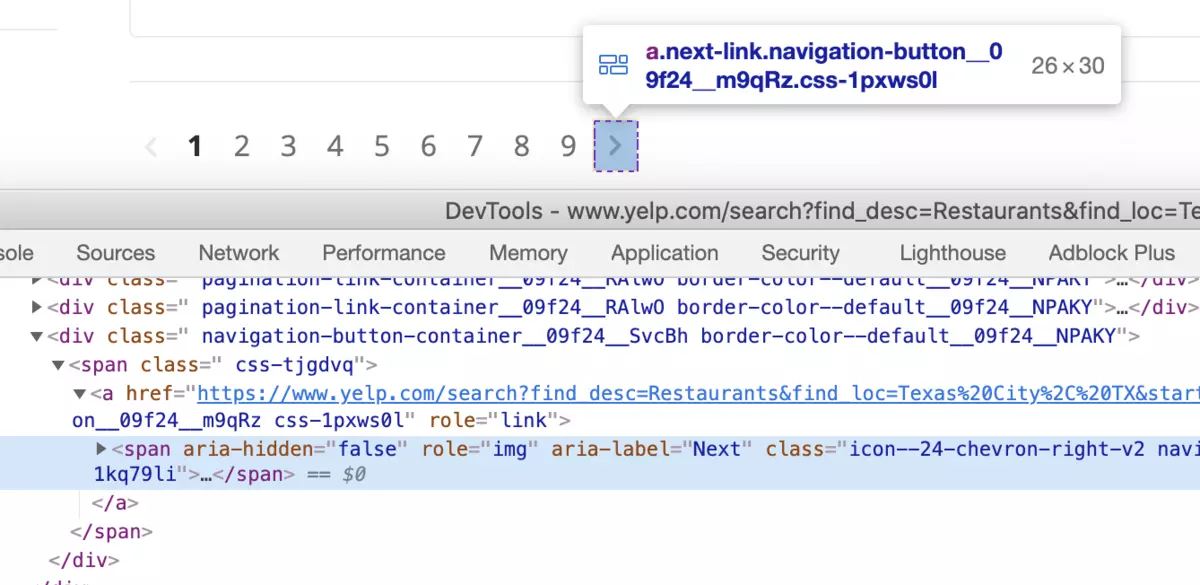
Now let's handle the pagination.
var next = document.querySelector('.next-link'); if(next) { next.click() }
 From this page, we will scrape the following attributes from each business:
From this page, we will scrape the following attributes from each business: - Name
- URL
- Reviews count
- Stars
- Thumbnail image
- Tags
Now, let's define the selectors for each attribute.
/* Parent: */
//*[@id='main-content']/div/ul/li[*]
/* Name */
h3
/* URL */
h3 a
/* Reviews count */
span[class^=reviewCount]
/* Stars */
div[role=img]
/* Thumbnail image */
img
/* Tags */
a[role=link] button p
Let's build the request that will scrape all the results that the search page returned.
export API_KEY=YOUR_PAGE2API_KEY
{
"url": "https://www.yelp.com/search?find_desc=Restaurants&find_loc=Redwood%20City%2C%20TX",
"premium_proxy": "us",
"merge_loops": true,
"scenario": [
{
"loop": [
{ "wait_for": "h3" },
{ "execute": "parse" },
{ "execute_js": "var next = document.querySelector('.next-link'); if(next) { next.click() }" }
],
"iterations": 3
}
],
"parse": {
"places": [
{
"_parent": "//*[@id='main-content']/div/ul/li[*]",
"_require": ["name", "url"],
"name": "h3 a >> text",
"url": "h3 a >> href",
"reviews_count": "span[class^=reviewCount] >> text",
"stars": "div[role=img] >> aria-label",
"thumbnail": "img >> src",
"tags": ["a[role=link] button p >> text"]
}
]
},
"real_browser": true
}
curl -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.yelp.com/search?find_desc=Restaurants&find_loc=Redwood%20City%2C%20TX",
"premium_proxy": "us",
"merge_loops": true,
"scenario": [
{
"loop": [
{ "wait_for": "h3" },
{ "execute": "parse" },
{ "execute_js": "var next = document.querySelector(\".next-link\"); if(next) { next.click() }" }
],
"iterations": 3
}
],
"parse": {
"places": [
{
"_parent": "//*[@id=\"main-content\"]/div/ul/li[*]",
"_require": ["name", "url"],
"name": "h3 a >> text",
"url": "h3 a >> href",
"reviews_count": "span[class^=reviewCount] >> text",
"stars": "div[role=img] >> aria-label",
"thumbnail": "img >> src",
"tags": ["a[role=link] button p >> text"]
}
]
},
"real_browser": true
}' 'https://www.page2api.com/api/v1/scrape' | python3.10 -mjson.tool
{
"result": {
"places": [
{
"name": "Palmer’s Restaurant Bar & Courtyard",
"url": "https://www.yelp.com/biz/palmers-restaurant-bar-and-courtyard-san-marcos?osq=Restaurants",
"reviews_count": "520",
"stars": "4 star rating",
"thumbnail": "https://s3-media0.fl.yelpcdn.com/bphoto/qNfJPDa27awAllb2Wa07pQ/348s.jpg",
"tags": [
"Bars",
"American (Traditional)",
"Steakhouses"
]
},
{
"name": "North Street",
"url": "https://www.yelp.com/biz/north-street-san-marcos?osq=Restaurants",
"reviews_count": "139",
"stars": "4.5 star rating",
"thumbnail": "https://s3-media0.fl.yelpcdn.com/bphoto/Ci3mK0aF2UFzkauMlIZaCg/348s.jpg",
"tags": [
"Indian",
"Beer Bar",
"Coffee & Tea"
]
}, ...
]
}, ...
}
How to scrape Yelp reviews
First what we need is to open any URL from the previous step.
https://www.yelp.com/biz/north-street-san-marcos?osq=Restaurants
The URL is the first parameter we need to perform the reviews scraping.
Luckily, the pagination handling is similar to the one described in the previous step, so we will use the same flow.
- Name
- Tags
- Phone number
- Address
- Reviews count
- Stars
and the following fields for each review:
- User
- Location
- Stars
- Content
Now, let's define the selectors for each attribute.
/* Name */
h1
/* Tags */
/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/span[3]/span[*]
/* Phone number */
//*[contains(text(),'Phone number')]/../p[2]
/* Address */
//*[contains(text(),'Get Directions')]/../../p[2]
/* Reviews count */
/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/div[2]/div[2]/span
/* Stars */
div[role=img]
/* --------- */
/* Reviews attibutes selectors: */
/* Parent */
ul li
/* User */
.user-passport-info span.fs-block
/* Location */
.user-passport-info div
/* Stars */
div[role=img]
/* Content */
span[lang=en]
Now it's time to prepare the request that will scrape Yelp reviews.
{
"url": "https://www.yelp.com/biz/north-street-san-marcos?osq=Restaurants",
"merge_loops": true,
"premium_proxy": "us",
"scenario": [
{
"loop": [
{ "wait_for": ".user-passport-info span.fs-block" },
{ "wait": 1 },
{ "execute": "parse" },
{ "execute_js": "var next = document.querySelector('.next-link'); if(next) { next.click() }" }
],
"iterations": 3
}
],
"parse": {
"name": "h1 >> text",
"tags": ["/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/span[3]/span[*] >> text"],
"phone": "//*[contains(text(),'Phone number')]/../p[2] >> text",
"address": "//*[contains(text(),'Get Directions')]/../../p[2] >> text",
"reviews_count": "/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/div[2]/div[2]/span >> text",
"stars": "div[role=img] >> aria-label",
"reviews": [
{
"_parent": "ul li",
"_require": ["user"],
"user": ".user-passport-info span.fs-block >> text",
"location": ".user-passport-info div >> text",
"stars": "div[role=img] >> aria-label",
"content": "span[lang=en] >> text"
}
]
},
"real_browser": true
}
curl -XPOST -H "Content-type: application/json" -d '{
"api_key": "'"$API_KEY"'",
"url": "https://www.yelp.com/biz/north-street-san-marcos?osq=Restaurants",
"merge_loops": true,
"premium_proxy": "us",
"scenario": [
{
"loop": [
{ "wait_for": ".user-passport-info span.fs-block" },
{ "wait": 1 },
{ "execute": "parse" },
{ "execute_js": "var next = document.querySelector(\".next-link\"); if(next) { next.click() }" }
],
"iterations": 3
}
],
"parse": {
"name": "h1 >> text",
"tags": ["/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/span[3]/span[*] >> text"],
"phone": "//*[contains(text(),\"Phone number\")]/../p[2] >> text",
"address": "//*[contains(text(),\"Get Directions\")]/../../p[2] >> text",
"reviews_count": "/html/body/yelp-react-root/div[1]/div[3]/div[1]/div[1]/div/div/div[2]/div[2]/span >> text",
"stars": "div[role=img] >> aria-label",
"reviews": [
{
"_parent": "ul li",
"_require": ["user"],
"user": ".user-passport-info span.fs-block >> text",
"location": ".user-passport-info div >> text",
"stars": "div[role=img] >> aria-label",
"content": "span[lang=en] >> text"
}
]
},
"real_browser": true
}' 'https://www.page2api.com/api/v1/scrape' | python3.10 -mjson.tool
{
"result": {
"name": "North Street",
"tags": [
"Indian,",
"Beer Bar,",
"Coffee & Tea"
],
"phone": "(512) 667-7094",
"address": "216 North St San Marcos, TX 78666",
"reviews_count": "139 reviews",
"stars": "4.5 star rating",
"reviews": [
{
"user": "Jeri T.",
"location": "Elite 2021",
"stars": "5 star rating",
"content": "My mom and I were looking for a new place in San Marcos ..."
},
{
"user": "Maribel D.",
"location": "Elite 2021",
"stars": "5 star rating",
"content": "Visiting San Marcos and North street popped up on my Yelp top restaurants ..."
}, ...
]
}, ...
}
Conclusion
Done!
In this article, you've learned how to scrape business information and reviews from Yelp with Page2API - a Web Scraping API that turns pages into JSON with ease.
