
Introduction
Zillow is a real estate company that offers various products targeted at both home buyers and sellers.
In this article, you will read about the easiest way to scrape real estate data from Zillow with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Zillow listings into Google Sheets.
You can scrape real estate data from Zillow, with such information as addresses, prices, descriptions, photos, URLs to perform:
- price monitoring
- trends analysis
- competitor analysis
Challenges
At first look, scraping Zillow doesn't seem to be a trivial task because of the following aspects:
- The content from the listing page is returned dynamically, based on scrolling events.
- The names of the CSS selectors are dynamically generated and cannot be used to pick the needed content, and we will use XPath selectors instead.
For this purpose, we will use Page2API - the scraping API that overtakes the challenges mentioned above with ease.
In this article, we will learn how to:
- Scrape Zillow listings
- Scrape Zillow Property data
Prerequisites
To start scraping, you will need the following things:
- A Page2API account
- A location, in which we want to search for listed properties, let's use for example Redwood City
- A property overview page from Zillow. We will pick a random property link from the page mentioned above.
How to scrape Zillow listings
First what we need is to open the 'Homes' page and type the name of the city that will show the properties we are searching for.
https://www.zillow.com/homes/
and search for 'Redwood City'
https://www.zillow.com/homes/Redwood-City,-CA_rb/
The resulted URL is the first parameter we need to start scraping the listings page.
The listings page must look similar to the following one:
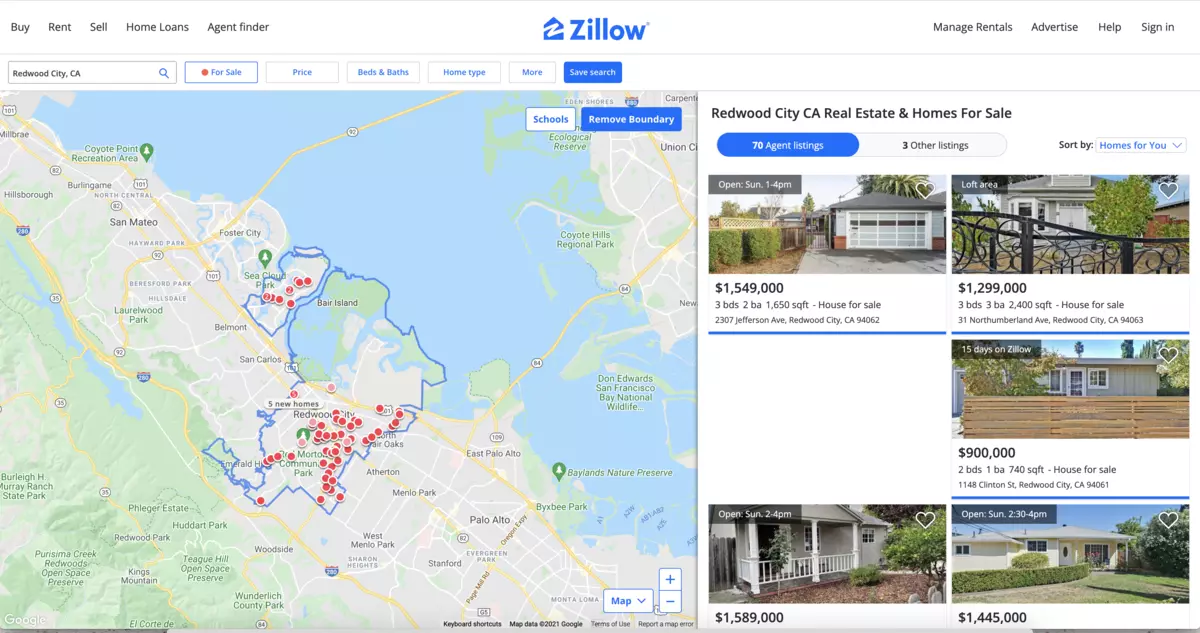
If you inspect the page HTML, you will find out that a single result is wrapped into an element that looks like the following:
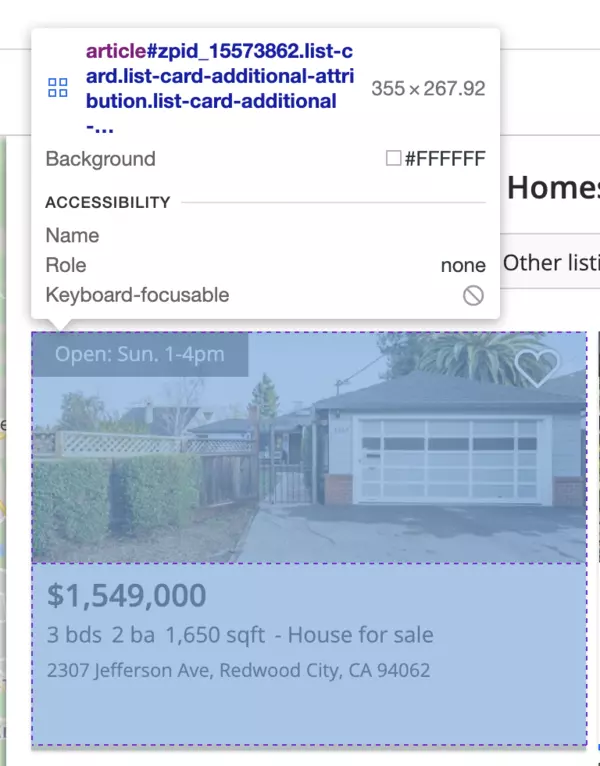
The HTML for a single result element will look like this:
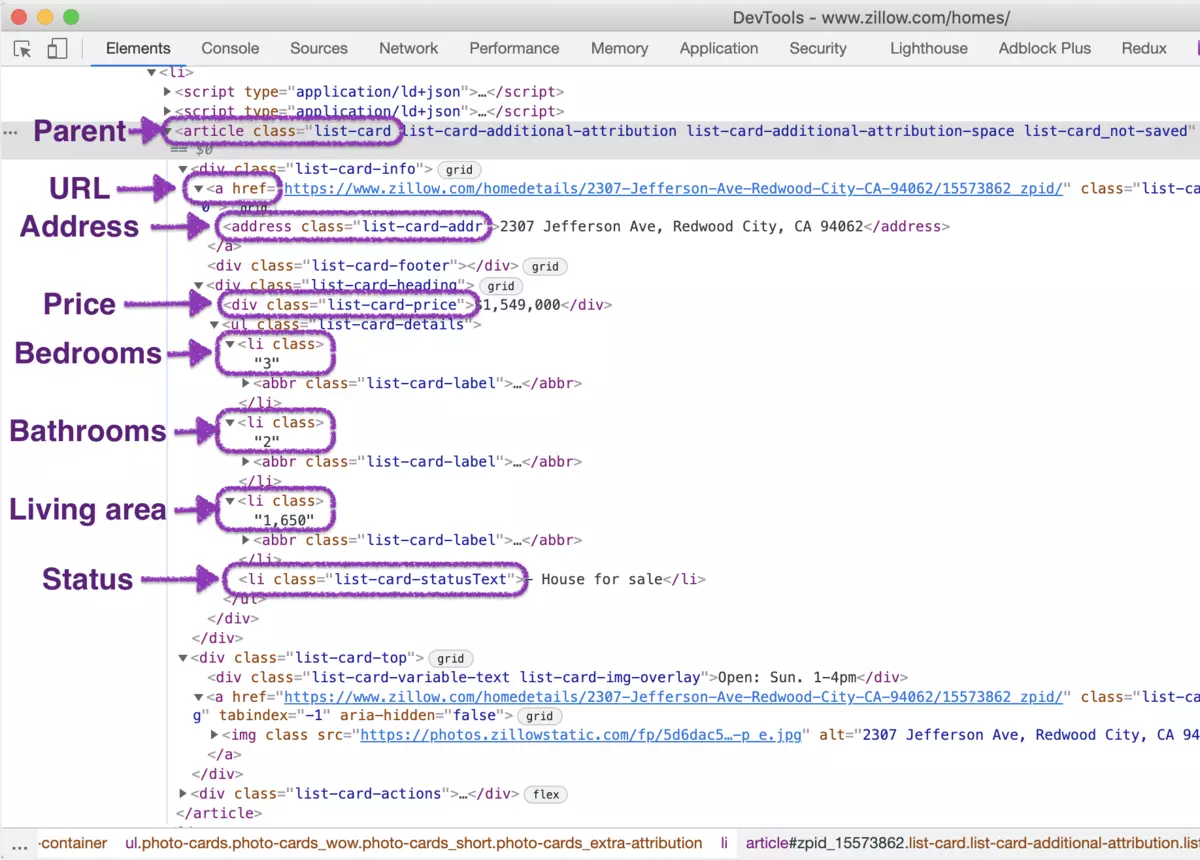
From the listing page, we will scrape the following attributes from each property:
- Price
- URL
- Bedrooms
- Bathrooms
- Living area
- Address
Each property container is wrapped in an article element with the following class: list-card.
Now, let's define the selectors for each attribute.
/* Parent: */
article.property-card
/* Price: */
.list-card-price
/* URL: */
a
/* Bedrooms: */
ul[class*=StyledPropertyCardHomeDetails] li:nth-child(1) b
/* Bathrooms: */
ul[class*=StyledPropertyCardHomeDetails] li:nth-child(2) b
/* Living area: */
ul[class*=StyledPropertyCardHomeDetails] li:nth-child(3) b
/* Address: */
[data-test=property-card-addr]
Next is the pagination handling.
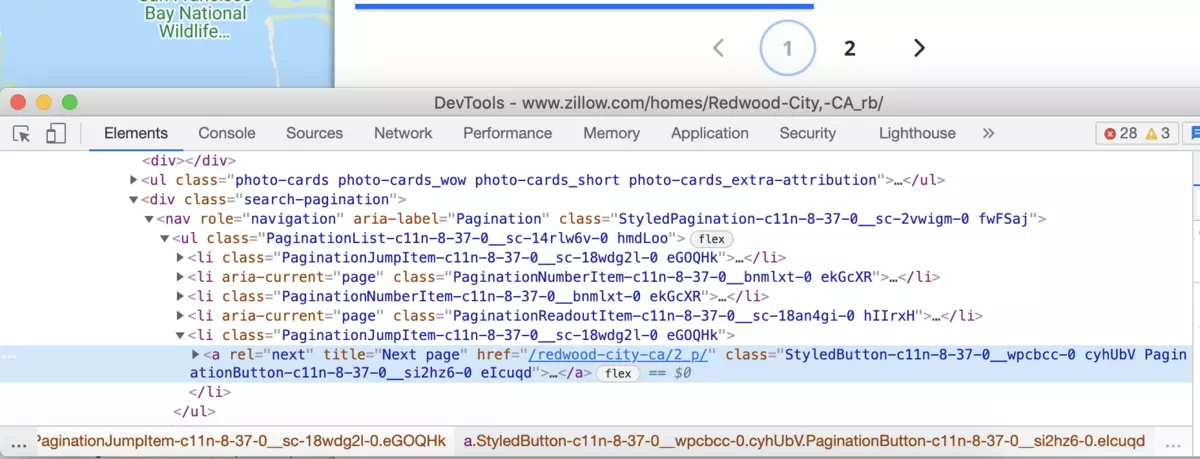 In our case, we must click on the next page link while the link will be active:
In our case, we must click on the next page link while the link will be active:
document.querySelector('.search-pagination a[rel=next]')?.click()
And stop our scraping request when the next page link became disabled.
In our case, a new attribute (disabled) is assigned to the pagination link.
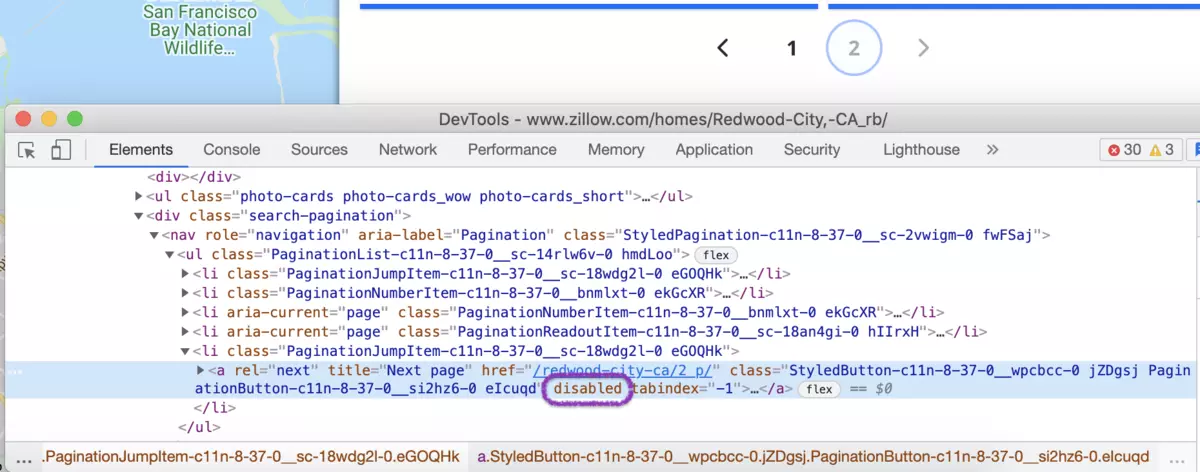 The stop condition for the pagination will look like this:
The stop condition for the pagination will look like this:
var next = document.querySelector('.search-pagination a[rel=next]'); next === null || next.getAttributeNames().includes('disabled')
// returns true if there is no next page
The last thing is handling the content that loads dynamically when we scroll down.
Usually, there are 40 items on the page, but when the page loads - it has only about 8 items.
To load all items we will do the next trick:
- Wait for the page to load
- Scroll down 3 times slowly, (with a short delay) until we see the last item
- Start scraping the page
Now let's build the request that will scrape all properties that the search page returned.
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.zillow.com/homes/Redwood-City,-CA_rb/",
"real_browser": true,
"merge_loops": true,
"premium_proxy": "de",
"scenario": [
{
"loop": [
{ "wait_for": "article.property-card" },
{ "execute_js": "var articles = document.querySelectorAll('article')"},
{ "execute_js": "articles[Math.round(articles.length/4)]?.scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute_js": "articles[Math.round(articles.length/2)]?.scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute_js": "articles[Math.round(articles.length/1.5)]?.scrollIntoView({behavior: 'smooth'})"},
{ "wait": 1 },
{ "execute": "parse"},
{ "execute_js": "document.querySelector('.search-pagination a[rel=next]')?.click()" }
],
"iterations": 5,
"stop_condition": "var next = document.querySelector('.search-pagination a[rel=next]'); next === null || next.getAttributeNames().includes('disabled')"
}
],
"parse": {
"properties": [
{
"url": "a >> href",
"price": "[data-test=property-card-price] >> text",
"_parent": "article.property-card",
"address": "[data-test=property-card-addr] >> text",
"bedrooms": "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(1) b >> text",
"bathrooms": "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(2) b >> text",
"living_area": "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(3) b >> text"
}
]
}
}
Note: we have to encode our js snippets in base64 to run the request in the terminal with cURL.
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.zillow.com/homes/Redwood-City,-CA_rb/",
real_browser: true,
merge_loops: true,
premium_proxy: "de",
scenario: [
{
loop: [
{ wait_for: "article.property-card" },
{ execute_js: "var articles = document.querySelectorAll('article')"},
{ execute_js: "articles[Math.round(articles.length/4)]?.scrollIntoView({behavior: 'smooth'})"},
{ wait: 1 },
{ execute_js: "articles[Math.round(articles.length/2)]?.scrollIntoView({behavior: 'smooth'})"},
{ wait: 1 },
{ execute_js: "articles[Math.round(articles.length/1.5)]?.scrollIntoView({behavior: 'smooth'})"},
{ wait: 1 },
{ execute: "parse"},
{ execute_js: "document.querySelector('.search-pagination a[rel=next]')?.click()" }
],
iterations: 5,
stop_condition: "var next = document.querySelector('.search-pagination a[rel=next]'); next === null || next.getAttributeNames().includes('disabled')"
}
],
parse: {
properties: [
{
url: "a >> href",
price: "[data-test=property-card-price] >> text",
_parent: "article.property-card",
address: "[data-test=property-card-addr] >> text",
bedrooms: "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(1) b >> text",
bathrooms: "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(2) b >> text",
living_area: "ul[class*=StyledPropertyCardHomeDetails] li:nth-child(3) b >> text"
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"properties": [
{
"price": "$600,000",
"url": "https://www.zillow.com/homedetails/464-Clinton-St-APT-211-Redwood-City-CA-94062/15638802_zpid/",
"bedrooms": "1 bd",
"bathrooms": "1 ba",
"living_area": "761 sqft",
"address": "464 Clinton St APT 211, Redwood City, CA 94062"
},
{
"price": "$2,498,000",
"url": "https://www.zillow.com/homedetails/3618-Midfield-Way-Redwood-City-CA-94062/15571874_zpid/",
"bedrooms": "4 bds",
"bathrooms": "4 ba",
"living_area": "2,960 sqft",
"address": "3618 Midfield Way, Redwood City, CA 94062"
},
...
]
}, ...
}
How to scrape Zillow property data
From the 'Homes' page, we click on any property.
https://www.zillow.com/homedetails/464-Clinton-St-APT-211-Redwood-City-CA-94062/15638802_zpid/
We will see something like this when we will inspect the page source:
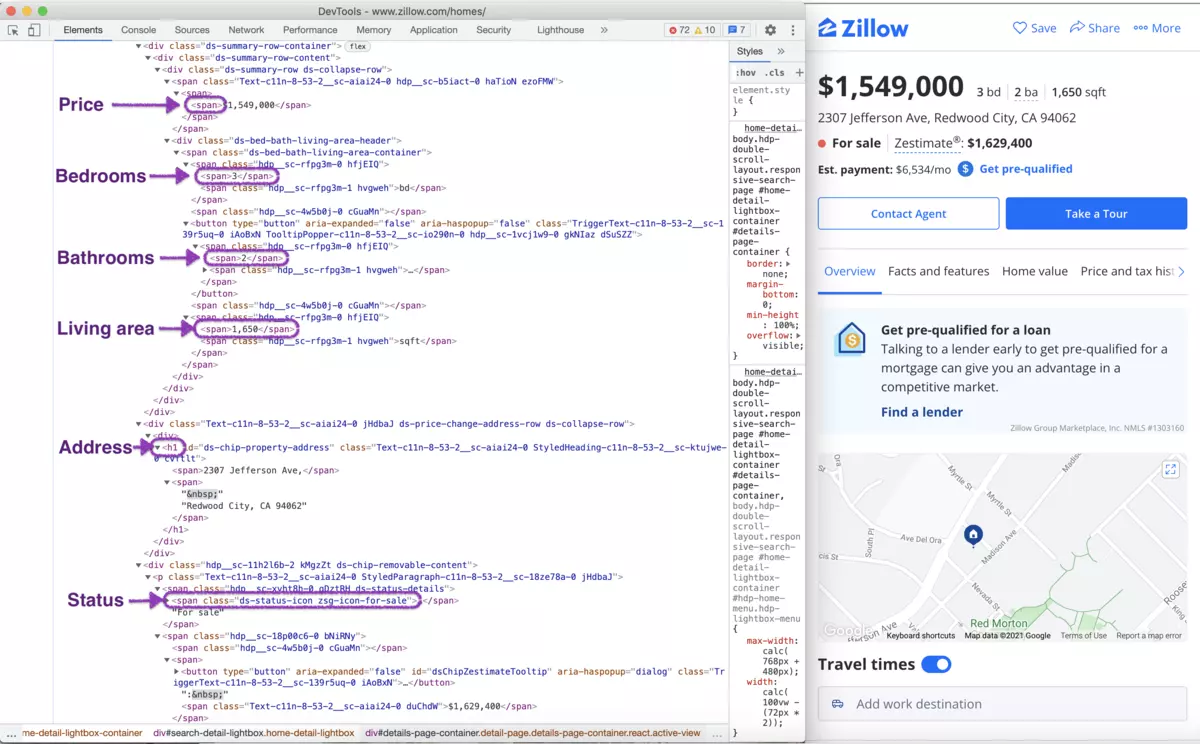
From this page, we will scrape the following attributes:
- Price
- Address
- Bedrooms
- Bathrooms
- Living area
- Time on Zillow
- Views
- Saves
- Images
Let's define the selectors for each attribute.
/* Price: */
[data-testid=price]
/* Address */
h1
/* Bedrooms: */
[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(1)
/* Bathrooms: */
button [data-testid=bed-bath-item]
/* Living area: */
[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(2)
/* Time on Zillow: */
//*[contains(text(),'on Zillow')]/../dt[1]/strong[1]
/* Views: */
//*[contains(text(),'on Zillow')]/../dt[2]/strong[1]
/* Saves: */
//*[contains(text(),'on Zillow')]/../dt[3]/strong[1]
/* Images: */
.media-stream-tile picture img
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.zillow.com/homedetails/264-Stuyvesant-Ave-4-Brooklyn-NY-11221/30604149_zpid/",
"premium_proxy": "de",
"real_browser": true,
"wait_for": "[data-testid=price]",
"parse": {
"price": "[data-testid=price] >> text",
"address": "h1 >> text",
"bedrooms": "[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(1) >> text",
"bathrooms": "button [data-testid=bed-bath-item] >> text",
"living_area": "[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(2) >> text",
"time_on_zillow": "//*[contains(text(),'on Zillow')]/../dt[1]/strong[1] >> text",
"views": "//*[contains(text(),'on Zillow')]/../dt[2]/strong[1] >> text",
"saves": "//*[contains(text(),'on Zillow')]/../dt[3]/strong[1] >> text",
"images": [
".media-stream-tile picture img >> src"
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: "https://www.zillow.com/homedetails/264-Stuyvesant-Ave-4-Brooklyn-NY-11221/30604149_zpid/",
real_browser: true,
premium_proxy: "de",
wait_for: "[data-testid=price]",
parse: {
price: "[data-testid=price] >> text",
address: "h1 >> text",
bedrooms: "[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(1) >> text",
bathrooms: "button [data-testid=bed-bath-item] >> text",
living_area: "[data-testid=bed-bath-beyond] [data-testid=bed-bath-item]:nth-of-type(2) >> text",
time_on_zillow: "//*[contains(text(),'on Zillow')]/../dt[1]/strong[1] >> text",
views: "//*[contains(text(),'on Zillow')]/../dt[2]/strong[1] >> text",
saves: "//*[contains(text(),'on Zillow')]/../dt[3]/strong[1] >> text",
images: [
".media-stream-tile picture img >> src"
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"price": "$2,300,000",
"address": "264 Stuyvesant Avenue UNIT 4, Bed-Stuy, NY 11221",
"bedrooms": "6 bd",
"bathrooms": "4 ba",
"living_area": "3,520 sqft",
"time_on_zillow": "2 days",
"views": "422",
"saves": "20",
"images": [
"https://photos.zillowstatic.com/fp/d05b64fcf5ee681f711c1974f305dd69-cc_ft_960.jpg",
"https://photos.zillowstatic.com/fp/8f6fac275b8eaa9151cf668d4d975608-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/09d0fa1829886680e9c1f16101b2d456-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/21fc3ea519bbf78a79a6c2e875a65ef4-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/d65c318f1af3bfdc882fa94150d145e8-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/f888fc996cbefda7eb87046fc9bf4660-cc_ft_576.jpg",
"https://photos.zillowstatic.com/fp/92ccb633c27684fa07756f21d4da01cc-cc_ft_576.jpg"
]
}
}
How to export Zillow listings to Google Sheets
In order to be able to export our Zillow listings to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "properties", "format": "csv"
}
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
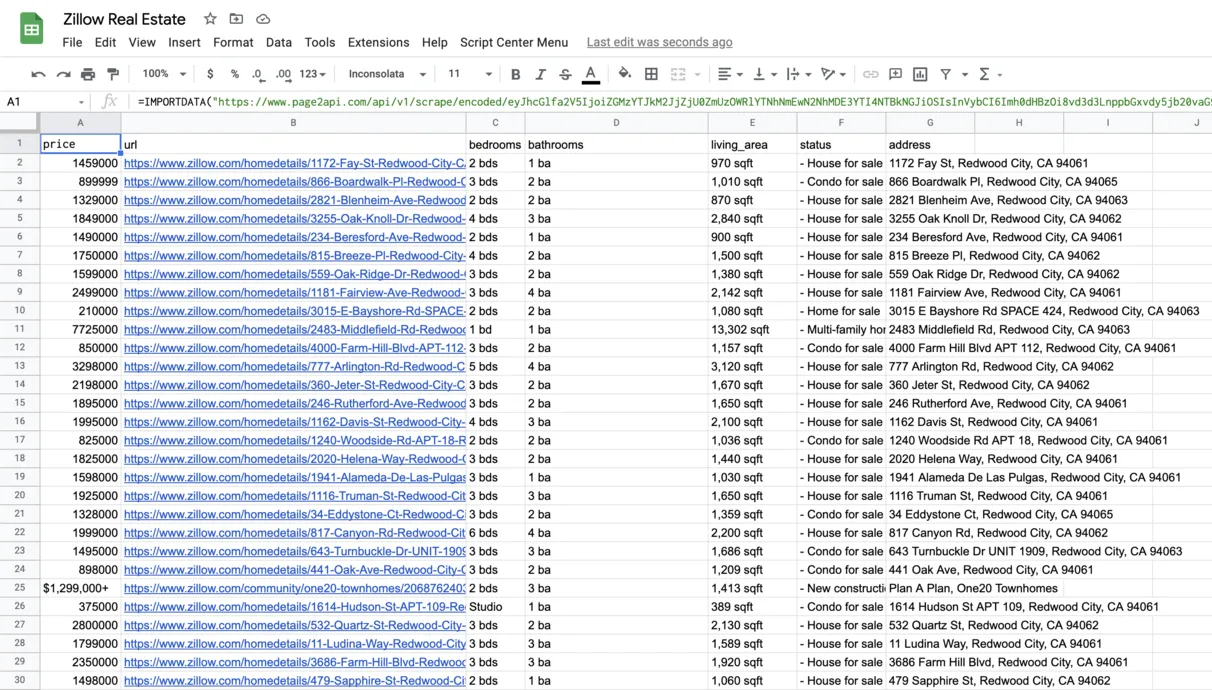
Conclusion
That's it!
In this article, you've discovered the easiest way to scrape a real estate website, such as Zillow, with Page2API - a Web Scraping API that handles any challenges for you.
