
Introduction
Glassdoor.com is an American website where current and former employees anonymously review companies.
In this article, you will read about the easiest way to scrape Glassdoor reviews with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL, and a No-Code solution that will import Glassdoor reviews into Google Sheets.
DISCLAIMER: we highly recommend you to scrape Glassdoor only for personal use.
For example: let's say you are looking for a new job and you want to quickly analyze the reviews for the company that you are interested in.
Prerequisites
To start scraping Glassdoor reviews, we will need the following things:
- A Page2API account
-
A company name that we are interested in.
In our case, the company that we are interested in is... Glassdoor.
(Which also has reviews on its website)
How to scrape Glassdoor Reviews
First what we need is to open glassdoor.com and type Glassdoor reviews into the search input.
https://www.glassdoor.com/Reviews/Glassdoor-Reviews-E100431.htm
We will use this URL as the first parameter we need to start the scraping process.
The page that you see must look like the following one:
If you inspect the page HTML, you will find out that a single review looks like the following:
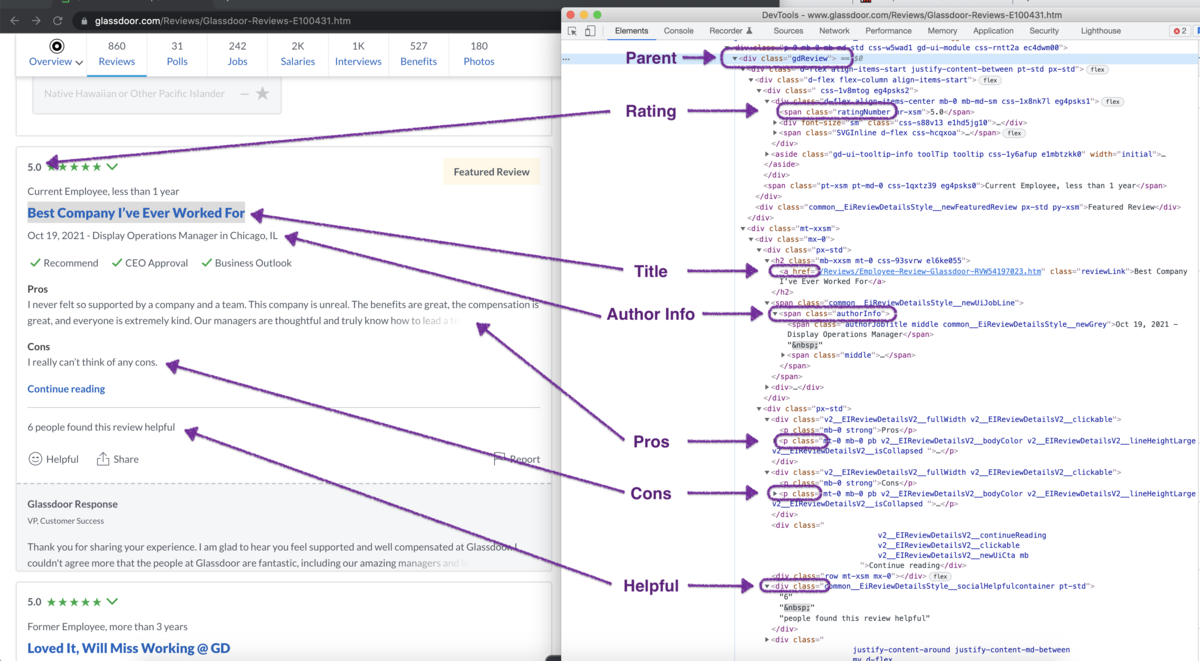 From the Glassdoor Reviews page, we will scrape the following attributes from each review:
From the Glassdoor Reviews page, we will scrape the following attributes from each review: - Title
- Author Info
- Date
- Rating
- Pros
- Cons
- Helpful
Now, let's define the selectors for each attribute.
/* Parent: */
#ReviewsFeed ol li
/* Title */
a[class*=module__title]
/* Author Info */
.review-details__review-details-module__employee
/* Date */
.review-details__review-details-module__reviewDate
/* Rating */
span[class*=overallRating]
/* Pros */
span[data-test=pros]
/* Cons */
span[data-test=cons]
/* Helpful */
span[class*=reviewHelpfulCount]
Let's handle the pagination.
There are two approaches that can help us scrape all the needed pages:
1. We can scrape the pages using the batch scraping feature
2. We can iterate through the pages by clicking on the Next page button
Now it's time to build the request that will scrape Glassdoor reviews.
The following examples will show how to scrape 5 pages of reviews from Glassdoor.com
{
"api_key": "YOUR_PAGE2API_KEY",
"real_browser": true,
"javascript": false,
"premium_proxy": "us",
"batch": {
"urls": "https://www.glassdoor.com/Reviews/Glassdoor-Reviews-E100431_P[1, 5, 1].htm",
"concurrency": 1,
"merge_results": true
},
"parse": {
"reviews": [
{
"_parent": "#ReviewsFeed ol li",
"title": "a[class*=module__title] >> text",
"author_info": ".review-details__review-details-module__employee >> text",
"date": ".review-details__review-details-module__reviewDate >> text",
"rating": "span[class*=overallRating] >> text",
"pros": "span[data-test=pros] >> text",
"cons": "span[data-test=cons] >> text",
"helpful": "span[class*=reviewHelpfulCount] >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
payload = {
api_key: 'YOUR_PAGE2API_KEY',
premium_proxy: 'us',
real_browser: true,
javascript: false,
batch: {
urls: "https://www.glassdoor.com/Reviews/Glassdoor-Reviews-E100431_P[1, 5, 1].htm",
concurrency: 1,
merge_results: true
},
parse: {
reviews: [
{
_parent: '#ReviewsFeed ol li',
title: 'a[class*=module__title] >> text',
author_info: '.review-details__review-details-module__employee >> text',
date: '.review-details__review-details-module__reviewDate >> text',
rating: 'span[class*=overallRating] >> text',
pros: 'span[data-test=pros] >> text',
cons: 'span[data-test=cons] >> text',
helpful: 'span[class*=reviewHelpfulCount] >> text'
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
Let's take a look at the Next page approach.
Note: the 'Next page' approach described below is for demonstrational purposes only.
We strongly recommend you use the 'Batch' approach whenever possible since it's faster and more reliable.
With this approach, to go to the next page, we must click on the next page button if it's present on the page:
document.querySelector(".nextButton")?.click()
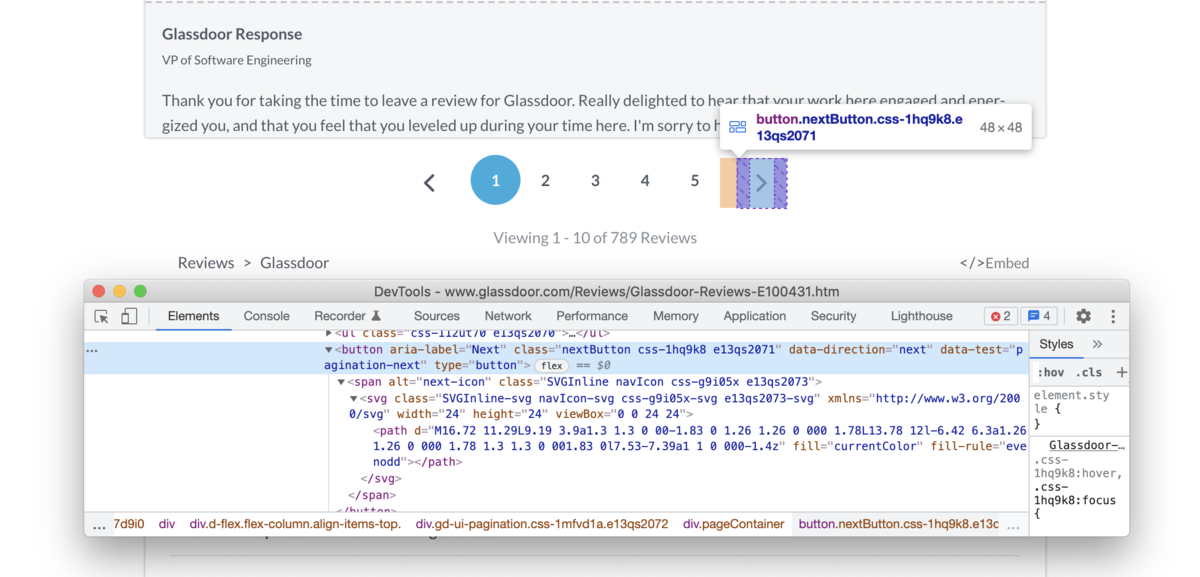
The scraping will continue while the next page button is present on the page, and stop if it disappears.
The stop condition for the scraper will be the following javascript snippet:
document.querySelector(".nextButton") === null
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.glassdoor.com/Reviews/Glassdoor-Reviews-E100431.htm",
"real_browser": true,
"merge_loops": true,
"premium_proxy": "us",
"scenario": [
{
"loop": [
{ "wait_for": "#ReviewsFeed ol li" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector(\".nextButton\")?.click()" }
],
"iterations": 5,
"stop_condition": "document.querySelector('.nextButton') === null"
}
],
"parse": {
"reviews": [
{
"_parent": "#ReviewsFeed ol li",
"title": "a[class*=module__title] >> text",
"author_info": ".review-details__review-details-module__employee >> text",
"date": ".review-details__review-details-module__reviewDate >> text",
"rating": "span[class*=overallRating] >> text",
"pros": "span[data-test=pros] >> text",
"cons": "span[data-test=cons] >> text",
"helpful": "span[class*=reviewHelpfulCount] >> text"
}
]
}
}
require 'rest_client'
require 'json'
api_url = 'https://www.page2api.com/api/v1/scrape'
payload = {
api_key: 'YOUR_PAGE2API_KEY',
url: 'https://www.glassdoor.com/Reviews/Glassdoor-Reviews-E100431.htm',
real_browser: true,
merge_loops: true,
premium_proxy: 'us',
scenario: [
{
loop: [
{ wait_for: '#ReviewsFeed ol li' },
{ execute: 'parse' },
{ execute_js: 'document.querySelector(".nextButton")?.click()' }
],
iterations: 5,
stop_condition: 'document.querySelector(".nextButton") === null'
}
],
parse: {
reviews: [
{
_parent: '#ReviewsFeed ol li',
title: 'a[class*=module__title] >> text',
author_info: '.review-details__review-details-module__employee >> text',
date: '.review-details__review-details-module__reviewDate >> text',
rating: 'span[class*=overallRating] >> text',
pros: 'span[data-test=pros] >> text',
cons: 'span[data-test=cons] >> text',
helpful: 'span[class*=reviewHelpfulCount] >> text'
}
]
}
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"reviews": [
{
"title": "Glassdoor Walks the Walk",
"author_info": "Senior Manager",
"date": "Jan 7, 2022",
"rating": "5.0",
"pros": "Glassdoor creates a positive environment for employees to learn and grow. ...",
"cons": "At any organization, there is always room for improvement. ...",
"helpful": "1 person found this review helpful"
},
{
"title": "Great Company To Work For",
"author_info": "Customer Success Manager",
"date": "Jan 5, 2022",
"rating": "4.0",
"pros": "I absolutely love working at Glassdoor. ...",
"cons": "While we do have more of an extensive career growth plan, ...",
"helpful": "2 people found this review helpful"
}, ...
]
}, ...
}
How to export Glassdoor reviews to Google Sheets
In order to be able to export our Glassdoor reviews to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "reviews", "format": "csv"
}
Please note that the batch URLs are defined explicitly to make it simpler to edit the payload.
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
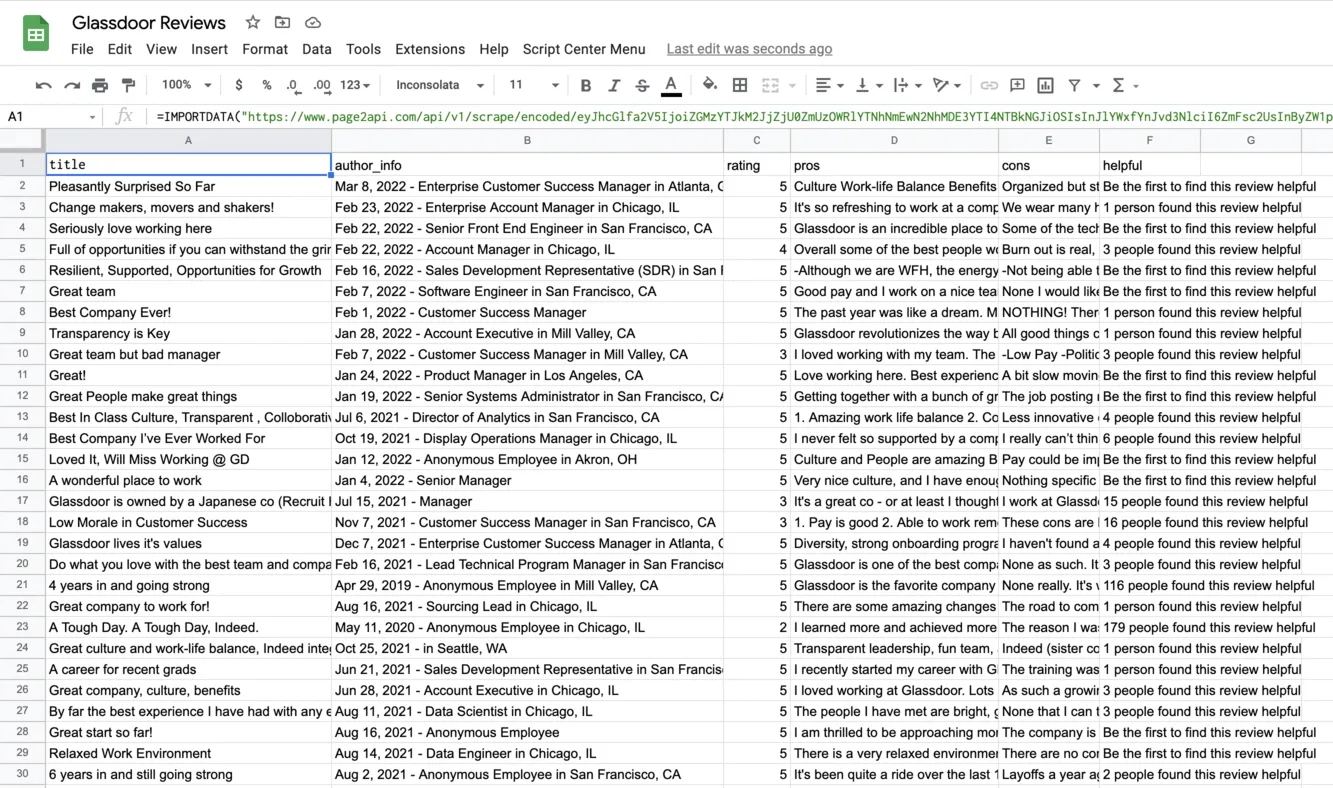
The result must look like the following one:
Conclusion
Done!
We just finished scraping the reviews from Glassdoor, and it turned to be easy and fun if we have the proper scraping tool.
