
Introduction
IMDB.com is one of the largest and most comprehensive movie databases, containing a vast collection of movie-related information such as movie titles, release dates, cast and crew details, ratings, and more.
If you're a movie enthusiast or data scientist looking to explore and analyze movie data, then IMDB is a great source of information.
However, manually collecting and analyzing this data can be a tedious and time-consuming task.
Fortunately, IMDB scraping offers a quick and efficient solution for automating this process.
In this article, you will read about the easiest way to scrape IMDB movies with Page2API.
You will find code examples for Ruby, Python, PHP, NodeJS, cURL for building an IMDB scraper and a No-Code solution that will help you import IMDB movies into Google Sheets.
Prerequisites
To start scraping IMDB movies, we will need the following things:
- A Page2API account
-
An IMDB movies list that we are interested in.
In our case, the list will be "Top 1000".
How to scrape IMDB Movies
First what we need is to open the "Top 1000" IMDB list.
https://www.imdb.com/search/title/?groups=top_1000
We will use this URL as the first parameter we need to start the scraping process.
The page that you see must look like the following one:
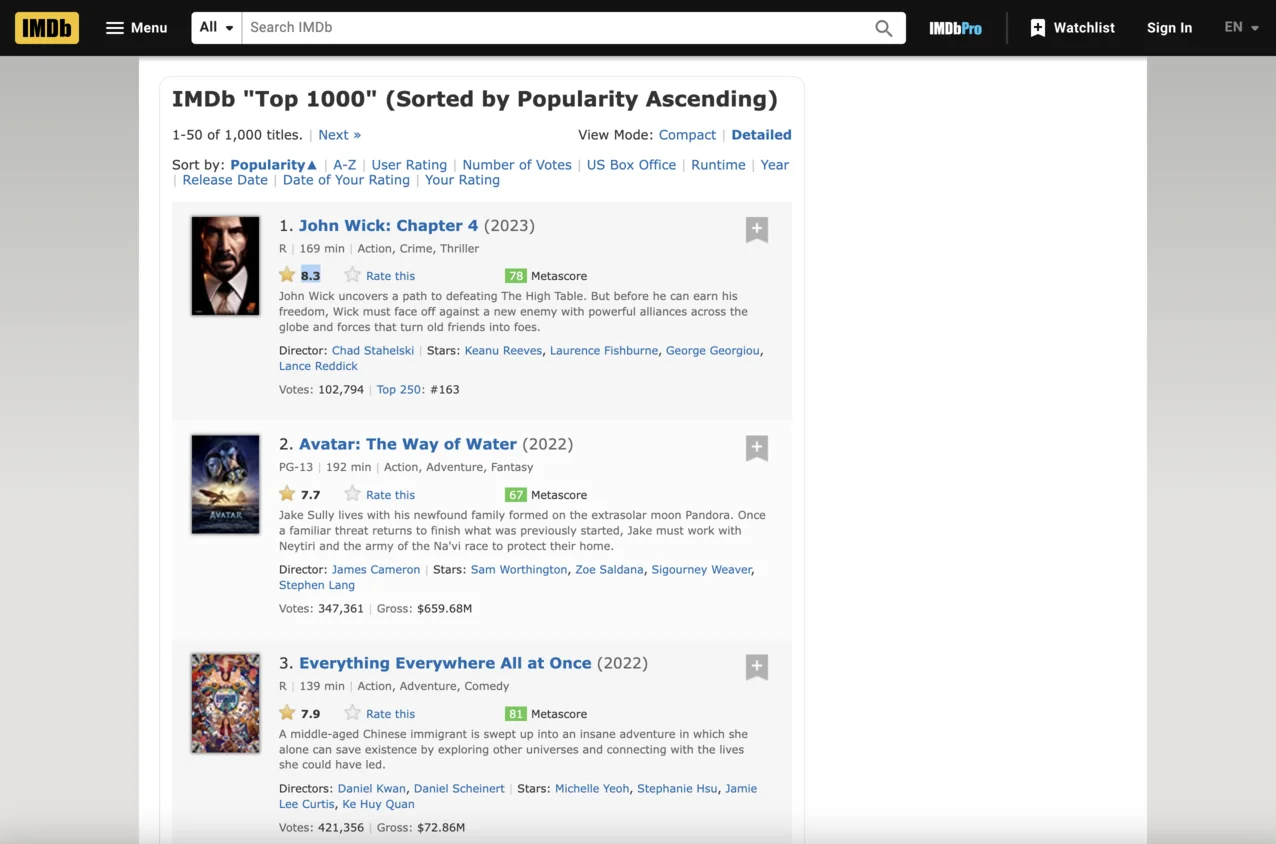 From the IMDB movies page, we will scrape the following attributes from each movie:
From the IMDB movies page, we will scrape the following attributes from each movie: - Title
- URL
- Year
- Genre
- Votes
- Rating
- Runtime
- Certificate
Now, let's define the selectors for each attribute.
/* Parent: */
.dli-parent
/* Title: */
.dli-parent-header
/* URL: */
.dli-parent-header a
/* Year: */
.dli-parent-year
/* Votes: */
[name=nv]
/* Rating: */
.ratings-imdb-rating
/* Runtime: */
.runtime
/* Certificate: */
.certificate
Let's handle the pagination.
There are two approaches that can help us scrape all the needed pages:
1. We can scrape the pages using the batch scraping feature
2. We can iterate through the pages by clicking on the Next page button
Now it's time to build the request that will scrape IMDB movies.
The following examples will show how to scrape 3 pages of movies from IMDB.com
{
"api_key": "YOUR_PAGE2API_KEY",
"batch": {
"urls": "https://www.imdb.com/search/title/?groups=top_1000&start=[1, 101, 50]",
"concurrency": 1,
"merge_results": true
},
"parse": {
"movies": [
{
"title": ".ipc-title-link-wrapper >> text",
"url": ".ipc-title-link-wrapper >> href",
"year": ".dli-title-metadata > span:nth-of-type(1)",
"votes": ".ipc-rating-star--voteCount >> text",
"rating": ".ipc-rating-star--rating >> text",
"_parent": ".dli-parent",
"runtime": ".dli-title-metadata > span:nth-of-type(2) >> text",
"certificate": ".dli-title-metadata > span:nth-of-type(3) >> text"
}
]
},
"datacenter_proxy": "us"
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
batch: {
urls: "https://www.imdb.com/search/title/?groups=top_1000&start=[1, 101, 50]",
concurrency: 1,
merge_results: true
},
parse: {
movies: [
{
title: ".ipc-title-link-wrapper >> text",
url: ".ipc-title-link-wrapper >> href",
year: ".dli-title-metadata > span:nth-of-type(1)",
votes: ".ipc-rating-star--voteCount >> text",
rating: ".ipc-rating-star--rating >> text",
_parent: ".dli-parent",
runtime: ".dli-title-metadata > span:nth-of-type(2) >> text",
certificate: ".dli-title-metadata > span:nth-of-type(3) >> text"
}
]
},
datacenter_proxy: "us"
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
Let's take a look at the Next page approach.
Note: the 'Next page' approach described below is for demonstrational purposes only.
We strongly recommend you use the 'Batch' approach whenever possible since it's faster and more reliable.
With this approach, to go to the next page, we must click on the next page button if it's present on the page:
document.querySelector(".next-page")?.click()
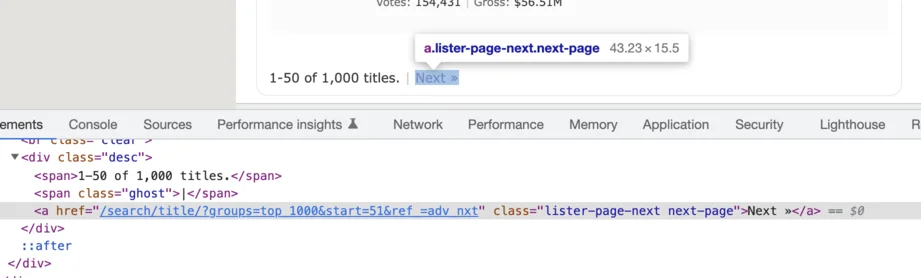
The scraping will continue while the next page button is present on the page, and stop if it disappears.
The stop condition for the scraper will be the following javascript snippet:
document.querySelector(".next-page") === null
{
"api_key": "YOUR_PAGE2API_KEY",
"url": "https://www.imdb.com/search/title/?groups=top_1000",
"real_browser": true,
"merge_loops": true,
"scenario": [
{
"loop": [
{ "wait_for": ".dli-parent" },
{ "execute": "parse" },
{ "execute_js": "document.querySelector('.next-page')?.click()" }
],
"stop_condition": "document.querySelector('.next-page') === null",
"iterations": 3
}
],
"parse": {
"movies": [
{
"title": ".ipc-title-link-wrapper >> text",
"url": ".ipc-title-link-wrapper >> href",
"year": ".dli-title-metadata > span:nth-of-type(1)",
"votes": ".ipc-rating-star--voteCount >> text",
"rating": ".ipc-rating-star--rating >> text",
"_parent": ".dli-parent",
"runtime": ".dli-title-metadata > span:nth-of-type(2) >> text",
"certificate": ".dli-title-metadata > span:nth-of-type(3) >> text"
}
]
},
"datacenter_proxy": "us"
}
require 'rest_client'
require 'json'
api_url = "https://www.page2api.com/api/v1/scrape"
payload = {
api_key: "YOUR_PAGE2API_KEY",
url: "https://www.imdb.com/search/title/?groups=top_1000",
real_browser: true,
merge_loops: true,
scenario: [
{
loop: [
{ wait_for: ".dli-parent" },
{ execute: "parse" },
{ execute_js: "document.querySelector('.next-page')?.click()" }
],
stop_condition: "document.querySelector('.next-page') === null",
iterations: 3
}
],
parse: {
movies: [
{
title: ".ipc-title-link-wrapper >> text",
url: ".ipc-title-link-wrapper >> href",
year: ".dli-title-metadata > span:nth-of-type(1)",
votes: ".ipc-rating-star--voteCount >> text",
rating: ".ipc-rating-star--rating >> text",
_parent: ".dli-parent",
runtime: ".dli-title-metadata > span:nth-of-type(2) >> text",
certificate: ".dli-title-metadata > span:nth-of-type(3) >> text"
}
]
},
datacenter_proxy: "us"
}
response = RestClient::Request.execute(
method: :post,
payload: payload.to_json,
url: api_url,
headers: { "Content-type" => "application/json" },
).body
result = JSON.parse(response)
puts(result)
{
"result": {
"movies": [
{
"title": "1. John Wick: Chapter 4 (2023)",
"url": "https://www.imdb.com/title/tt10366206/?ref_=adv_li_tt",
"year": "(2023)",
"votes": "103,371",
"rating": "8.3",
"runtime": "169 min",
"certificate": "R"
},
{
"title": "2. Avatar: The Way of Water (2022)",
"url": "https://www.imdb.com/title/tt1630029/?ref_=adv_li_tt",
"year": "(2022)",
"votes": "347,882",
"rating": "7.7",
"runtime": "192 min",
"certificate": "PG-13"
}, ...
]
}, ...
}
How to export IMDB movies to Google Sheets
In order to be able to export the IMDB movies to a Google Spreadsheet we will need to slightly modify our request to receive the data in CSV format instead of JSON.According to the documentation, we need to add the following parameters to our payload:
"raw": {
"key": "movies", "format": "csv"
}
Please note that the batch URLs are defined explicitly to make it simpler to edit the payload.
The URL with encoded payload will be:
Press 'Encode'
Note: If you are reading this article being logged in - you can copy the link above since it will already have your api_key in the encoded payload.
Press 'Encode'
The result must look like the following one:
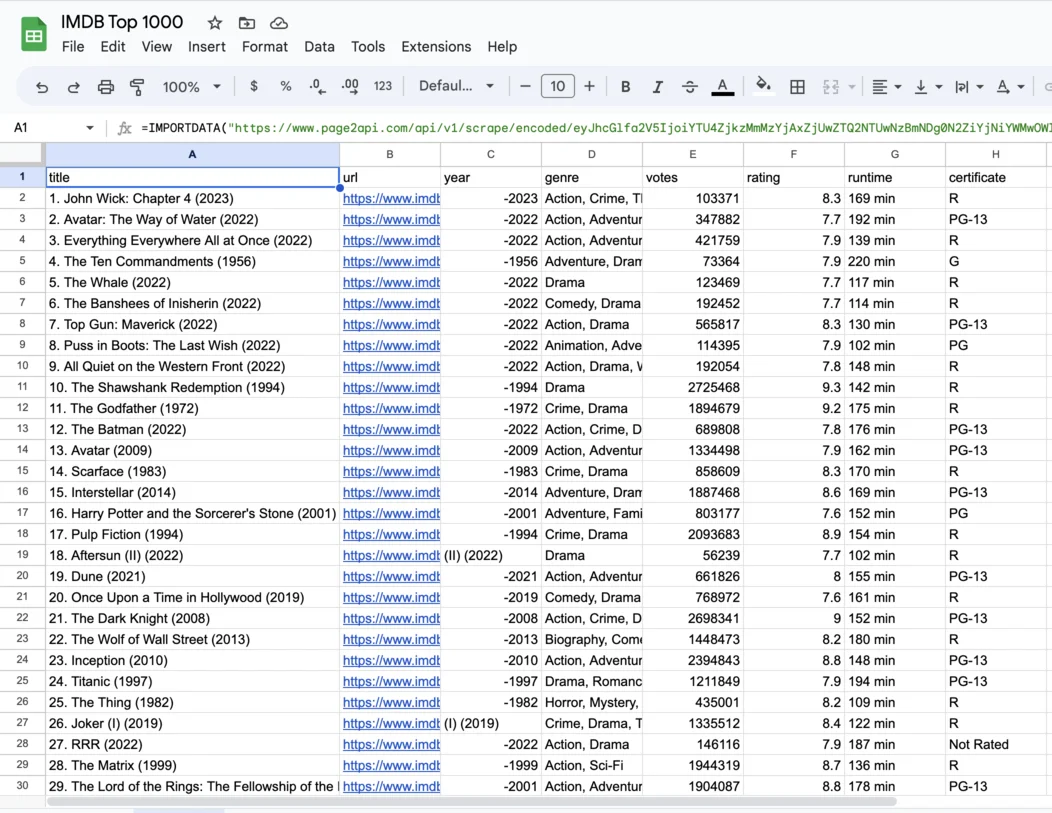
Conclusion
In conclusion, web scraping is an efficient and powerful tool for collecting and analyzing data from websites.
IMDB.com provides a rich source of movie-related information, and with Page2API, you can easily and quickly scrape this data for analysis.
In this blog post, we covered a step-by-step guide on how to scrape IMDB movie data using Page2API.
We explored various techniques for collecting and parsing data from IMDB, including batch scraping, handling pagination, and extracting specific elements like movie titles and ratings, and more.
With the knowledge and techniques covered in this blog post, you can now start exploring IMDB's vast collection of movie data and use it for a variety of applications, from research and analysis to building your own movie recommendation engine.
